



test
test
 invalid-file
invalid-file<HEAD>
<TITLE>자바 스크립트 쿠키 셋팅, 추출, 삭제 예제</TITLE>
<STYLE type="text/css">
table{ font-size:9pt; }
</STYLE>
<SCRIPT>
/**
* 쿠키값 추출
* @param cookieName 쿠키명
*/
function getCookie( cookieName )
{
var search = cookieName + "=";
var cookie = document.cookie;
// 현재 쿠키가 존재할 경우
if( cookie.length > 0 )
{
// 해당 쿠키명이 존재하는지 검색한 후 존재하면 위치를 리턴.
startIndex = cookie.indexOf( cookieName );
// 만약 존재한다면
if( startIndex != -1 )
{
// 값을 얻어내기 위해 시작 인덱스 조절
startIndex += cookieName.length;
// 값을 얻어내기 위해 종료 인덱스 추출
endIndex = cookie.indexOf( ";", startIndex );
// 만약 종료 인덱스를 못찾게 되면 쿠키 전체길이로 설정
if( endIndex == -1) endIndex = cookie.length;
// 쿠키값을 추출하여 리턴
return unescape( cookie.substring( startIndex + 1, endIndex ) );
}
else
{
// 쿠키 내에 해당 쿠키가 존재하지 않을 경우
return false;
}
}
else
{
// 쿠키 자체가 없을 경우
return false;
}
}
/**
* 쿠키 설정
* @param cookieName 쿠키명
* @param cookieValue 쿠키값
* @param expireDay 쿠키 유효날짜
*/
function setCookie( cookieName, cookieValue, expireDate )
{
var today = new Date();
today.setDate( today.getDate() + parseInt( expireDate ) );
document.cookie = cookieName + "=" + escape( cookieValue ) + "; path=/; expires=" + today.toGMTString() + ";"
}
/**
* 쿠키 삭제
* @param cookieName 삭제할 쿠키명
*/
function deleteCookie( cookieName )
{
var expireDate = new Date();
//어제 날짜를 쿠키 소멸 날짜로 설정한다.
expireDate.setDate( expireDate.getDate() - 1 );
document.cookie = cookieName + "= " + "; expires=" + expireDate.toGMTString() + "; path=/";
}
/**
* 자신이 지정한 값으로 쿠키 설정
*/
function setMyCookie()
{
setCookie( form.setName.value, form.setValue.value, form.expire.value );
viewCookie(); // 전체 쿠키 출력 갱신
}
/**
* 자신이 지정한 쿠키명으로 확인
*/
function getMyCookie()
{
alert( "쿠키 값 : " + getCookie( form.getName.value ) );
}
/**
* 자신이 지정한 쿠키명으로 쿠키 삭제
*/
function deleteMyCookie()
{
deleteCookie( form.deleteName.value );
alert("쿠키가 삭제되었습니다.");
viewCookie();
}
/**
* 전체 쿠키 출력
*/
function viewCookie()
{
if( document.cookie.length > 0 )
cookieOut.innerText = document.cookie;
else
cookieOut.innerText = "저장된 쿠키가 없습니다.";
}
</SCRIPT>
</HEAD>
<body onLoad = "viewCookie()">
<form name = "form">
<table cellpadding = "0" cellspacing = "0">
<tr>
<td bgcolor = "#666666">
<table cellpadding = "0" cellspacing = "1">
<tr height = "25">
<td align = "center"><font color = "#ffffff">쿠키 설정</font></td>
</tr>
<tr>
<td bgcolor = "#ffffff" align = "center">
쿠키명 : <input type = "text" name = "setName"><br>
쿠키값 : <input type = "text" name = "setValue"><br>
기한 : <input type = "text" name = "expire"><br>
<input type = "button" onClick = "setMyCookie()" value = "쿠키설정">
</td>
</tr>
</table>
</td>
</tr>
</table>
<br>
<table cellpadding = "0" cellspacing = "0">
<tr>
<td bgcolor = "#666666">
<table cellpadding = "0" cellspacing = "1">
<tr height = "25">
<td align = "center"><font color = "#ffffff">쿠키 확인</font></td>
</tr>
<tr>
<td bgcolor = "#ffffff" align = "center">
쿠키명 : <input type = "text" name = "getName"><br>
<input type = "button" onClick = "getMyCookie()" value = "쿠키확인">
</td>
</tr>
</table>
</td>
</tr>
</table>
<br>
<table cellpadding = "0" cellspacing = "0">
<tr>
<td bgcolor = "#666666">
<table cellpadding = "0" cellspacing = "1">
<tr height = "25">
<td align = "center"><font color = "#ffffff">쿠키 삭제</font></td>
</tr>
<tr>
<td bgcolor = "#ffffff" align = "center">
쿠키명 : <input type = "text" name = "deleteName"><br>
<input type = "button" onClick = "deleteMyCookie()" value = "쿠키삭제">
</td>
</tr>
</table>
</td>
</tr>
</table>
<br>
<table cellpadding = "0" cellspacing = "0">
<tr>
<td bgcolor = "#666666">
<table cellpadding = "0" cellspacing = "1">
<tr height = "25">
<td align = "center"><font color = "#ffffff">전체 쿠키</font></td>
</tr>
<tr height = "25">
<td bgcolor = "#ffffff" align = "center">
<div id = "cookieOut"></div>
</td>
</tr>
</table>
</td>
</tr>
</table>
</form>
</body>
</html>
tes
test
1
1
1
11
1
test
 invalid-file
invalid-file1. Cookie 개요
Cookie는 사용자가 방문한 웹 사이트에서 추후에 어떤 용도로든 사용하기 위해서 사용자의 하드디스크에 남기는 정보를 의미한다. 예를 들어 사용자가 특정 팝업창에 대해 "더 이상 띄우지 않음", "오늘은 띄우지 않음" 등과 같은 체크 박스를 선택할 경우 다음부터 해당 사이트에 방문할 때 더 이상 그런 팝업창이 나타나지 않게 되는데 이는 Cookie 정보가 사용자의 PC에 저장되어 있기 때문이다. 엄밀히 말하자면 이런 Cookie는 Persistent Cookie라고 불리우며 메모리 공간에 상주하여 브라우저 관련 프로세스가 실행되고 있을 때까지만 유효한 Cookie 정보도 있는데 이를 Non-Persistent Cookie 혹은 Session Cookie라고 부른다.
2. Cookie 종류
Cookie의 종류에는 Persistent Cookie와 Session Cookie(Non-Persistent Cookie)가 있다. 이 두 개를 비교하면 다음과 같다.
|
비교 항목 |
Persistent Cookie |
Session Cookie |
|
저장 위치 |
디스크매체(text 파일) |
브라우저가 사용하는 메모리 공간 |
|
초기 접속 시 전송 여부 |
초기 접속 시 전송 |
서버로부터의 Set-Cookie로 할당되어야 메모리 공간에 나타나므로 초기 접속 시 전송되지 않음 |
|
Cookie의 만료 시기 |
Cookie 항목에 대해 설정된 expiration date가 지난 경우, 사용자가 Cookie를 삭제한 경우 |
사용자가 브라우저를 종료한 경우, 서버가 Set-Cookie로 Cookie 항목의 내용을 클리어한 경우 |
|
주요 용도 |
사용자가 사이트 재방문 시 속성 (팝업창 제한, ID, Password 등)을 기억하기 위함 |
사용자가 사이트 접속 시 인증 정보를 유지하기 위함 |
3. Cookie 동작 원리
클라이언트가 웹서버에 접속할 때 Cookie가 어떤 식으로 교환되는지 살펴보기로 하자.
우선 클라이언트가 해당 서버에 대한 Persistent Cookie를 저장하고 있다면 저장하고 있는 Cookie 정보가 만료되었는지 여부를 확인하여 만료되지 않았다면 해당 Cookie 정보를 보낸다. 이 정보는 Request Header에 포함되어 전달된다.
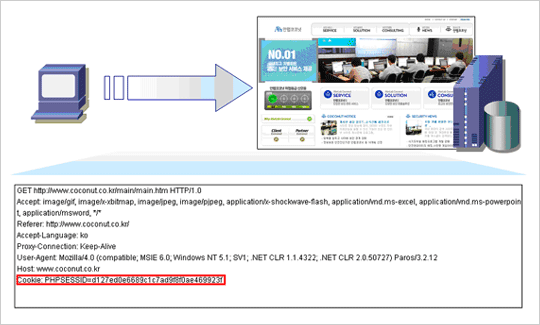
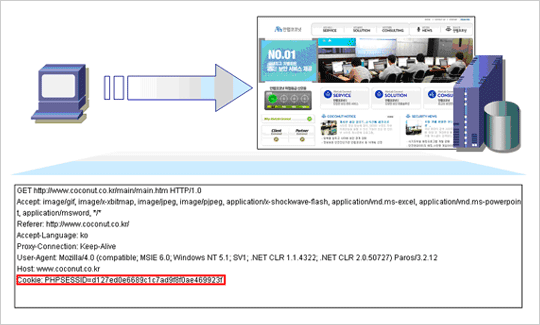
클라이언트는 해당 Cookie 정보를 받아들이거나 무시할 수 있지만 특별한 브라우저 설정을 하지 않았고 Set-Cookie가 규약을 만족한다면 받아들이는 것이 기본이다. 다음에 해당 웹서버로 클라이언트가 요청을 하게 될 경우 앞서 보냈던 쿠키 정보에 Set-Cookie에 의해 새로이 추가된 쿠키 정보를 포함하여 보낸다.
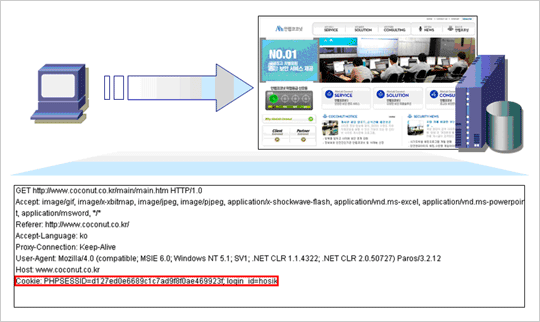
Set-Cookie 설정 이후 Request Header에 포함된 Cookie 정보
여기서 웹서버가 브라우저에 보내는 Set-Cookie를 좀 더 상세히 보자. Set-Cookie는 다음과 같은 정보가 포함될 수 있다.
|
필드 |
설명 |
|
NAME=VALUE |
(Required) 쿠키 변수 이름과 쿠키 변수 값을 지정한다. 앞서 예제의 경우에는 login_id가 NAME, hosik이 VALUE가 된다. |
|
Comment=Comment |
(Optional) Cookie에는 개인 정보가 포함되는 경우가 있다. 따라서 해당 Cookie가 어떤 용도로 사용되는 Cookie인지 사용자에게 알리기 위한 용도로 Comment를 추가한다. 사용자는 Comment 정보로 판단하여 해당 Cookie를 허용할지 않을지 여부를 결정할 수 있다. |
|
Domain=Domain |
(Optional) Cookie 정보가 유효한 도메인을 말한다. 어떤 사이트의 경우에는 하나의 인증 받은 정보를 다른 URL에서도 사용해야 하는 경우가 있다. 예를 들어 www.coconut.co.kr을 통해 인증 받았지만 file.coconut.co.kr이라는 URL에도 같은 정보가 유지되어야 하는 경우이다. 이런 경우 Domain=.coconut.co.kr이라는 정보를 추가로 쓰게 되며 Domain 값으로는 반드시 \'.\' 문자가 선행되어야 한다. (ex. Domain=file.coconut.co.kr (X), Domain=.coconut.co.kr (O)) |
|
Path=path |
(Optional) 어떤 경로에 해당 Cookie가 적용될지를 의미한다. Path=/ 라고 한다면 모든 경로에 적용되며 Path=/download/ 라고 한다면 /download/ 이하의 경로에 적용된다. |
|
Max-Age=delta-seconds |
(Optional) Cookie의 lifetime을 의미하며 delta-seconds가 경과하면 클라이언트는 Cookie를 버려야 한다. 해당 값은 0 이상으로 셋팅될 수 있으며 0으로 셋팅된 것은 해당 쿠키값이 바로 버려져야 한다는 것을 의미한다. |
|
Secure |
(Optional) 해당 Cookie는 secure channel로 전송되어야만 함을 의미한다. |
|
Version=Version |
(Required ) Version은 10진수의 정수로 표현될 수 있다. Cookie의 버전을 의미하며 Version=1로 표현된다. |
브라우저에 전송된 Set-Cookie가 악의적인 경우에 대처하기 위해 브라우저는 다음과 같은 경우 쿠키 정보를 거부할 수 있다.
- Domain 값이 \'.\'으로 시작되지 않는 경우
- 요청한 호스트 정보와 Domain의 값이 무관한 경우
- 요청한 호스트가 FQDN(IP 주소 형태가 아님)의 형태를 가질 때 요청한 호스트의 FQDN에서 Domain 값을 제외한 나머지, 즉 호스트명이 \'.\'을 하나 이상 포함하는 경우
(예를 들면 다음과 같음)
청한 호스트의 FQDN이 www.coconut.co.kr인데 Domain 값이 .co.kr 혹은 .kr인 경우
4. Cookie 파일 저장 위치 및 구조
Cookie(엄밀히 Persistent Cookie) 파일이 저장되는 위치, 그리고 저장 방식은 웹 브라우저 종류와 버전에 따라 상이하다. 예를 들어 Netscape Navigator 4.x 버전은 User Preference 폴더에 cookies.txt라는 파일 하나로 저장하였으며 Opera 4.x 버전은 cookies4.dat라는 파일로서 Opera 디렉토리에 저장한다. 국내에서 가장 많은 유저가 사용하는 인터넷익스플로러의 경우는 도메인마다 파일 하나로서 저장한다. 또한 저장되는 위치는 Windows 버전에 따라 다를 수 있다. 따라서 Cookie 파일을 찾기 위해서는 \'파일 찾기\'등의 검색 툴을 이용하여 검색어로서 \'Cookie\'를 입력하여 로컬하드디스크를 확인해보는 것이 쉽다.
이중 윈도우에 저장된 인터넷익스플로러의 Cookie 파일의 예를 보자. 다음은 로컬하드디스크에저장된 hosik@google[1].txt의 내용을 메모장으로 열어 본 경우이다.
|
PREF |
여기서 PREF는 Cookie의 Name이며 , ID=e86917dffe2b57c6.. (생략) .. S=R4sPpGRTj7axz2nH 는 Cookie의 Value, google.com/는 Cookie가 사용되는 Domain과 Path를 의미하며 1536은 해당 Cookie가 Secure하지 않음을 의미한다. 이렇게 Cookie 파일 그 자체로서 내용을 분석하는 것은 까다로운 문제이다. IECookieView라는 툴을 이용하면 다음과 같이 저장된 Cookie 내용들을 쉽게 열람하고 분석할 수 있다.
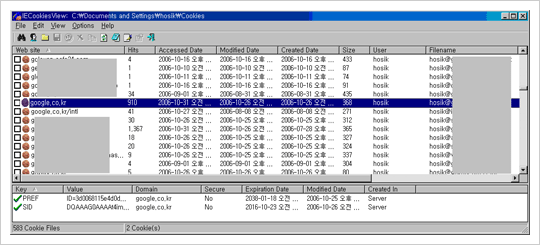
Persistent Cookie의 경우에는 사용자의 하드디스크에 저장된다. 특히 PC방이나 전산실, 도서관 등과 같은 공용 PC 환경에 저장된 하드디스크에 저장된 Cookie 정보는 쉽게 얻어낼 수 있다. 앞서 언급한 IECookieView 등을 통하여 종종 사용자의 ID, 비밀번호를 얻어내는 그런 직접적인 시도가 아니더라도 사용자의 ID, 비밀번호가 암호화된 형태로 저장되어 있을 때 해당 Cookie 값을 그대로 복사해와서 ID, 비밀번호 인증 절차를 거치지 않고 로그인할 수 있다. 이 경우는 자동로그인을 활성화한 거의 모든 사이트의 경우 ID, 비밀번호와 같은 중요 인증 정보를 Persistent Cookie로서 저장하기에 발생하는 문제이다.
5.1.1 XSS, XST 등의 취약점을 이용
XSS는 Cross Site Scripting의 약자로 CSS로 표기되지 않는 이유는 Cascading Style Sheet와 그 약자가 동일하기 때문에 혼동이 될 수 있어서이다. XST는 HTTP 메소드 중 디버깅을 위한 용도의 TRACE라는 메소드를 이용하는 것으로 Cross Site Tracing으로 XSS에 비해 진보된 공격 기법이다. XSS를 통한 Cookie Theft는 Cookie 옵션을 이용하여 근본적인 차단 방법이 있기에 이런 방법을 구현한 사이트에 대해서는 XST 기법을 사용한다. XSS, XST를 이용하는 경우에는 브라우저 프로세스 실행 중에만 유지되는 Session Cookie와 같은 정보도 얻어낼 수 있다.
XSS 취약성은 클라이언트 레벨에서 의도치 않은 스크립트(자바스크립트)가 실행되도록 하는 것이다. XSS 취약성을 응용한 공격 형태를 몇 가지 제시하면 다음과 같다.
ㅈ- 게시판에 HTML 태그(<script> 등)를 포함하는 방법
- Flash의 ActionScript를 이용하는 방법
- 웹 서버 취약성을 이용하여 URL에 HTML 태그 추가
`` http://www.victim.com/<script>alert(document.cookie)</script>
- 웹 어플리케이션의 취약성을 이용하여 파라미터에 HTML 태그 추가
```http://www.victim.com/hole.asp?q=<script>alert(document.cookie)</script>
아래 그림은 XSS 취약성을 이용한 일례이다. 게시판에 악성 스크립트를 포함하여 사용자가 원하지 않는 대화상자가 계속하여 나타나도록 만든 것이다.
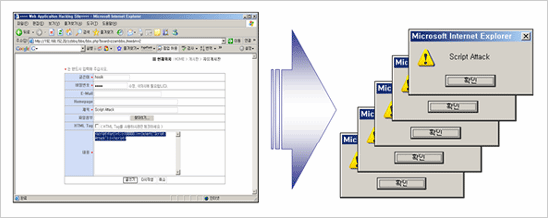
XSS 취약성을 이용한 악성 스크립트 실행
이번에는 XSS 취약성을 이용하여 사용자의 Cookie 정보를 얻어내려는 시도를 해보겠다. 다음과 같이 그림 파일을 하나 포함하여 마우스커서를 그림파일 위로 이동하면 get_cookie.php가 실행되어 Cookie 정보를 저장하도록 한다.
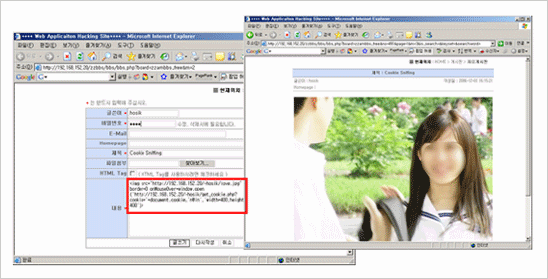
XSS 취약성을 이용한 Cookie Theft 시도
위의 예시에서는 게시판을 포함한 사이트와 공격을 위한 이미지 파일과 get_cookie.php 파일이 동일한 사이트인 192.168.152.20에 저장되고 있지만 실제 공격 시에는 공격을 위한 이미지 파일과 get_cookie.php는 공격자가 Cookie 정보를 저장하고자 하는 사이트에 웹 사이트를 구성하여 저장한다.
get_cookie.php의 내용은 유포시 공격에 사용될 위험이 있음으로 생략 하도록 하겠다. 어느 정도의 웹 프로그래밍 지식이 있다면 개별적으로 구현을 해 보는 것도 좋을 것 같다.
저자가 구현해 놓은 get_cookie.php파일 내용에는 사용자의 IP 주소, Cookie가 노출된 시간, 노출된 Cookie 정보를 getcook.txt 파일로서 저장한다. 이제 일반 사용자가 해당 게시물의 그림을 보는 순간 다음과 같은 해당 사용자의 Cookie 내용이 공격자가 만들어둔 사이트의 getcook.txt 파일로서 저장된다.
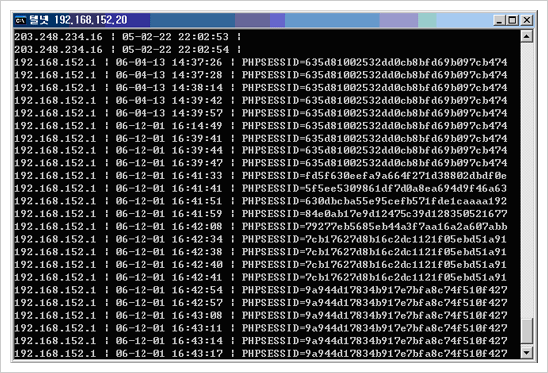
Cookie Theft 결과 얻어낸 Cookie
○ XST 취약성을 이용
XSS 취약성을 이용한 Cookie Theft는 매우 위협적이다. 이 방법을 근본적으로 차단할 수 있도록 하기 위한 메커니즘이 있는데 이는 다음달 연재에서 자세히 다루겠다. 이런 메커니즘이 적용된 Cookie의 경우에는 XSS 취약성으로 얻어낼 수 없다. 이 경우 사용하는 것이 TRACE 메소드를 이용한 XST(Cross Site Tracing)이다. 이 공격 기법에 대한 상세한 내용은 언급하지 않겠다.
5.1.2 스니핑 기법을 이용
Cookie는 패킷 스니핑을 통하여 요청에 포함된 Cookie 헤더 필드를 통해서도 얻어낼 수 있다. 유선랜 환경과 무선랜 환경의 경우로 나누어 알아 본다.
○ Wired LAN
다음은 Ethereal을 통하여 실제로 특정 사이트에 대한 접속 시 Cookie 정보를 얻어낸 화면이다.
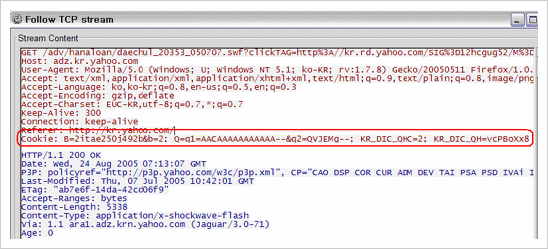
Ethereal을 통한 Cookie Theft
패킷 스니핑까지 할 수 있는 환경이라면 아예 Cookie 대신 로그인 시 전송되는 ID, Password 정보를 얻는 것이 더 현명할 수도 있겠다고 판단할 수 있다. 맞는 말이지만 로그인 과정이 SSL 등으로 암호화하여 전송되어 ID, Password를 얻을 수 없는 경우에 얻어낸 Cookie 정보는 매우 도움이 된다. 물론 접속 이후에도 모든 통신 과정이 SSL로 암호화되어 이루어진다면 스니핑으로도 Cookie 정보는 얻어낼 수 없지만 보안 수준이 매우 높지 않은 대부분의 사이트(즉 금융권 등을 제외한 사이트)는 로그인 과정에 전달되는 ID, Password 정도만 SSL 암호화를 적용하고 있음을 기억하자. 물론 심지어는 그런 최소한의 암호화도 안하고 있는 사이트도 많다.
두 번째로 의문을 가질 수 있는 점은 패킷 스니핑이 그렇게 쉬운가 하는 점이다. 유선랜 환경에서는 허브 환경이라 사용자의 모든 트래픽을 복사하여 아무 포트에서나 쉽게 다른 사용자의 트래픽을 볼 수 있는 방법, 혹은 스위치 환경이나 스위치를 제어할 수 있어서 특정 포트를 mirroring 포트로 지정하여 보는 방법이 있을 수 있다. 물론 이것도 저것도 아니면 ARP Redirect 등과 같은 기법을 쓸 수도 있으나 이러한 방법들은 최소한 중요한 정보를 얻고자하는 네트워크 내에 공격자가 포함되어 있어야 한다.
○ Wireless LAN
무선랜 환경에서는 스니핑을 통해 중요한 정보를 얻는 것이 매우 쉬워졌다. 무선랜 환경에서 패킷의 송수신은 안테나를 통해 전파를 수신하여 모든 사람이 라디오를 청취하는 것과 같아서 주파수만 맞추면 누구나 그 패킷을 수신할 수 있다. 그리고 그 주파수란 몇 개 되지 않는 값으로 그것을 맞추는 일은 아주 쉽다. 이러한 공격 기법에 대한 대응책으로서 보안 의식이 있는 네트워크 관리자는 자사가 보유한 AP(Access Point) 장비에 WEP, WPA 등과 같은 암호화를 적용하기도 하지만 아직도 단지 MAC 주소 인증만으로 어느 정도의 보안 조치를 끝냈다고 생각하는 관리자는 너무도 많다.
다음 그림은 AiroPeek를 통한 스니핑 결과 화면이다.
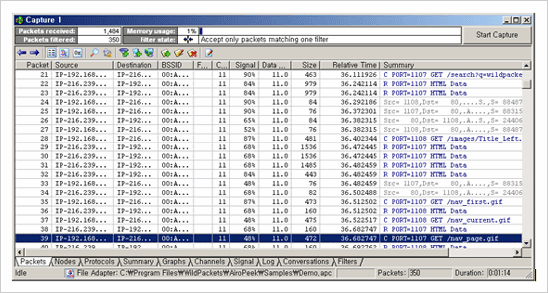
AiroPeek 를 통한 스니핑
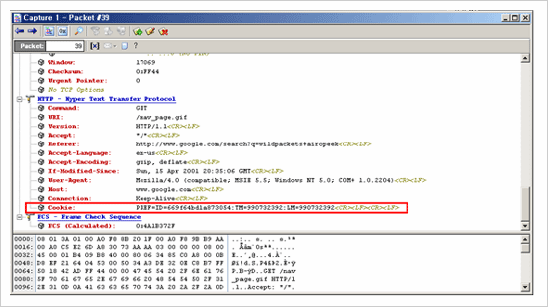
스니핑을 통한 Cooke 정보 획득
5.2 Cookie 정보 활용
여기까지 HTTP Session으로 이용되는 Cookie 값들을 수집하는 방법등을 알아 보았다. 그러면 이러한 방법들을 이용하여 Cookie를 수집하는 이유는 무엇일까?
5.2.1 개인정보 유출
저자는 지금 이 글을 읽고 있는 여러분이 직접 개인이 가입된 웹 사이트에 가서 Cookie값을 확인 해 봤으면 한다
가입된 웹 사이트에 로그인을 한 후 아래 그림과 같이 주소입력 창에
javascript

저자가 가입된 웹 사이트 쿠키값
여러분들은 어떻게 결과 값이 나타나고 있는가?
저자의 쿠키값에는 계정과 이름 그리고 메일주소가 설정되어 있어, 누군가가 이 정보를 가지고 가면 저자의 정보들을 획득 할 수 있을 것이다. 만일, 이 쿠키값에 위 정보외에 주민 번호, 주소, 전화번호, 핸드폰번호등이 있다고 가정하면 자기 자신의 모든 개인정보들이 나도 모르게 외부에 알려지게 된다. 그 예로 2004년 1사분기 Cookie에 포함된 개인정보가 유출된 사례로서 많은 사이트가 주민등록번호, 실명 정보 등을 쿠키에 포함하여 노출한 사례가 발견된 바 있었다.
기사 제목 대검 등 주요 사이트 개인정보 무방비 노출 ( 기사 내용 (일부) 국가 최고 수사기관, 공중파 방송사, 유명 신문사, 1천만명이 넘는 회원을 가진 커뮤니티 등 주요 웹사이트 상당수가 암호화 미비로 개인정보를 고스란히 노출, 타인 명의를 도용한 불법선거운동, 허위 투서, 명예훼손, 사기 등에 악용될 우려가 매우 높은 것으로 나타났다. 24일 네트워크와 보안업계에 따르면 주요 웹사이트 상당수가 서버와 PC 사이의 로그인과 접속유지를 위해 반복 교환하는 쿠키(cookieㆍ용어설명 참조)에 주민등록 번호, 실명, 실제 주소, e-메일 주소, 전화번호, 연령, 성별 등의 정보를 암호화되지 않은 평문으로 담는 방식을 사용, 이같은 문제점이 빚어지고 있다.
……(이하 생략) ……
5.3 사용자 도용(Cookie Spoofing)
매번 사용자가 로그인할 때마다 랜덤한 값으로 생성되는 일회용 토큰 형태의 Cookie 값을 이용한 인증을 하지 않는 사이트의 경우, 얻어낸 타 사용자의 Cookie 정보를 이용하여 다른 사용자로 로그인할 수 있다. Cookie를 위조하는 공격 기법이라고 하여 이를 Cookie Spoofing이라고 한다. Cookie Spoofing에는 도용하고자 하는 대상 사용자(희생자)의 Cookie 정보가 필요하지 않은 경우와 Cookie 정보가 필요한 경우가 있는데 전자와 후자를 각각 ‘단순 사용자 도용’, ‘Cookie Theft와 연계한 사용자 도용’으로 나누어 설명하도록 한다. 그 전에 잠시 ParosProxy 툴에 대해 알아보자.
5.3.1 ParosProxy의 소개
Cookie를 조작하기 위해서는 클라이언트가 서버에 Cookie 헤더를 보내는 중간에, 혹은 서버가 클라이언트에게 Set-Cookie 헤더를 보내는 중간에 요청과 응답을 가로채어 수정해야 한다. 물론 브라우저 자체가 그런 기능을 제공하는 경우도 있지만(일례로 FireFox의 플러그인 TamperData가 있음) Proxy 계열의 점검 도구를 사용하는 것이 편리하다. 이런 툴의 경우 또 다른 Proxy Server를 다시 Proxy Server로 잡는 Proxy Chain 기능, Request, Response에 대한 저장 및 분석, Web Spidering(Crawling), 또한 SQL Injection, CRLF Injection 등의 보안 취약성 검사 기능 등의 유용한 기능을 제공하기 때문이다. 그러한 툴 중에 프리웨어로서 유명한 툴이 ParosProxy이다. 이 툴은 http://www.parosproxy.org/에서 다운로드할 수 있으며 설치 과정은 단순하므로 생략한다. 툴 설치 이전에 JRE(Java Runtime Environment)가 설치되어 있어야 하며 버전은 ParosProxy에서 요구하는 버전으로 설치하여야 한다.
ParosProxy 툴 설정이 끝난 이후, www.coconut.co.kr 사이트에 접속한 이후 ParosProxy에서볼 수 있는 결과 화면이다. 다음과 같이 요청과 응답의 내용을 헤더를 포함하여 상세히 볼 수 있다.
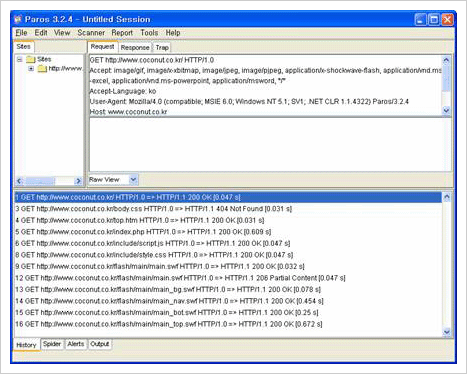
ParosProxy Example
5.3.2 단순 사용자 도용
이 장에서 공격 기법을 설명하기 위해 구현된 사이트는 다음과 같다. ID, Password 정보를 입력하면 로그인할 수 있는 사이트로 Cookie Spoofing을 이용한 사용자 도용을 설명하기 위해 임의로 구현한 사이트이다. 하지만 현재 실환경으로 운영되는 많은 사이트도 이런 문제점을 갖고 있음을 간과하지 말아야 한다.
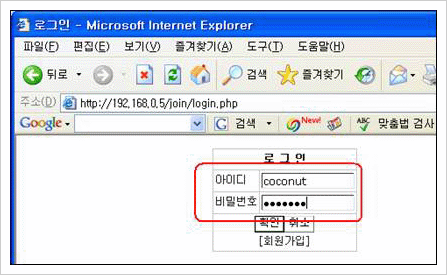
로그인 시도 화면
위 사이트는 일반적인 로그인 페이지다. 로그인할 경우 다음과 같이 해당 회원에 대한 정보를 열람하는 페이지가 확인된다.

로그인 성공 결과
물론 ID, Password를 잘못 입력하면 다음과 같은 오류 화면이 나타나는 일반적인 로그인 페이지이다.

로그인 실패 결과
로그인한 이후 회원정보변경 페이지가 열릴 때의 요청을 ParosProxy를 통해 확인해 보면 아래와 같이 s_id라는 Cookie 값이 ‘coconut’으로 셋팅되었음을 알 수 있다.
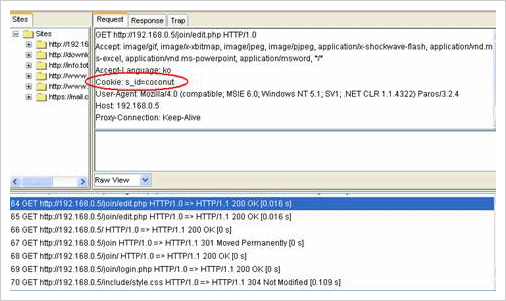
로그인 성공 이후 확인된 Cookie Header
이 Cookie 정보를 토대로 사용자의 인증 정보를 유지하며 또한 사용자가 coconut임을 구분하는 것으로 유추할 수 있다. 그렇다면 이것을 다른 값으로 바꾼다면 어떤 현상이 나타날 수 있을까? 그 이전에 로그인 과정에서 앞서 이야기한 Set-Cookie라는 Response Header가 확인되는지를 보자.
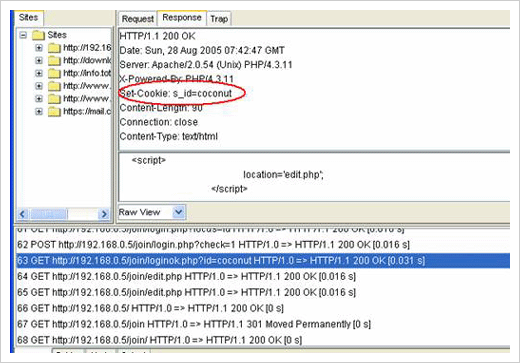
로그인 성공 시 확인된 Set-Cookie 정보
ParosProxy에 저장된 요청과 응답 내용을 보니 Set-Cookie라는 헤더가 나타나는 것을 볼 수 있다. 그렇다면 이 Set-Cookie 값을 중간에 가로채서 다른 값으로 변경해버리면 클라이언트가 이후에 보내게 될 Cookie 값도 다른 값으로 보내지게 될 것이다. 정말 그런지 확인해 보자.
ParosProxy를 이용할 경우 Set-Cookie 값을 중간에 가로채어 조작하는 방법은 크게 두 가지가 있다. 우선 Trap 기능을 이용하는 것이다. Trap 기능은 다음과 같이 활성화할 수 있다. Trap request를 선택하게 되면 클라이언트에서 서버 측으로 보내지는 데이터를 중간에 가로채어 조작하도록 할 것이며 Trap response를 선택하게 되면 서버 측에서 클라이언트로 보내지는 데이터를 중간에 가로채어 조작하도록 할 것이다.
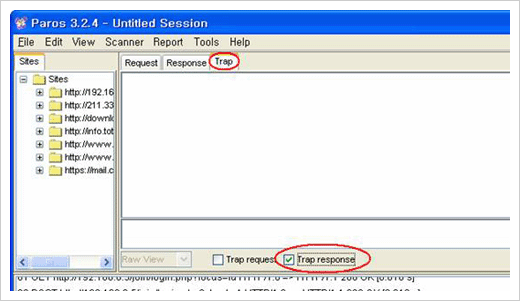
Trap response 설정
두 번째 방법은 Tools > Filter 메뉴에서 Detect and alert ’Set-cookie’ attempt in HTTP response for modification을 활성화 하는 것이다.
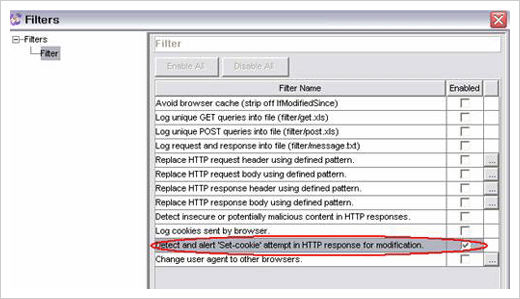
Set-cookie 시도 탐지 설정
두 번째 방법으로 할 경우 모든 응답 메시지를 가로채지 않고 Set-cookie 헤더가 나타났을 때만 가로채어 조작할 수 있도록 한다. 두 가지 중 어느 방법이든 가능하니 편한 방법을 쓰면 된다. 여기서는 Trap을 이용한 방법으로 기술하겠다.
우선 앞서 제시된 것과 같이 Trap Response 항목을 체크한다. Set-Cookie의 경우는 서버가 클라이언트에게 보내는 데이터를 조작하는 것이므로 Trap Response를 하는 것으로 충분하다.
Trap response를 셋팅한 상태에서 다시 로그인을 시도해본다. 요청에 대하여 응답을 계속 중간에 가로채어 보여줄텐데 Continue 버튼을 클릭하면 다음 단계로 넘어간다. 다음과 같이 Set-Cookie 화면이 나타날 때까지 넘어간다.
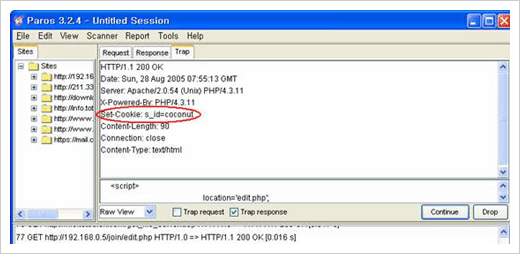
Trap 기능을 이용한 Set-Cookie 정보 변경 시도
여기서 Continue를 누르기 전에 Set-Cookie의 내용을 다음과 같이 조작한다.
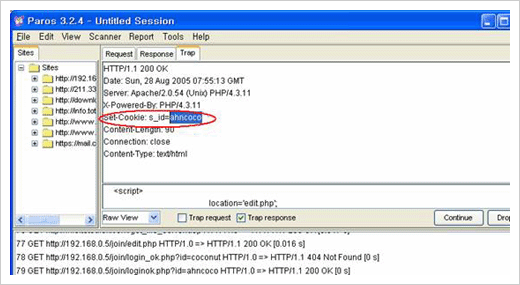
Trap 기능을 이용한 Set-Cookie 정보 변경 시도
이제 Continue를 누른다. 그 전에 더 이상의 response를 중간에 가로챌 이유는 없으므로 Trap response 체크박스는 해제해도 좋다. 그 결과 다음과 같이 ahncoco 계정의 패스워드 정보를 입력하지도 않았고 알지도 못함에도 ahncoco로서 로그인 성공하였음을 알 수 있다.
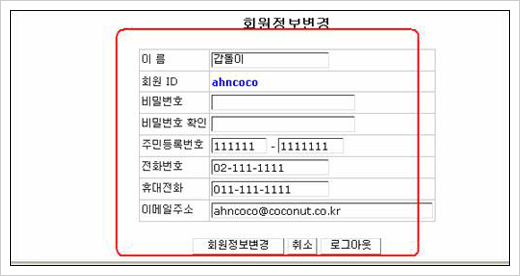
사용자 도용 성공 결과
이 예제에서는 이해를 돕게 하기 위하여 상황을 최대한 단순화시켰다. 하지만 s_id라는 ID 이름 대신 숫자로 표현된 값으로 사용자를 구분하는 경우도 실제로 구현된 사이트 중에 있다. 즉 hosik은 12341, ahncoco는 12342라고 표현되었다고 하자. 이 경우 Cookie 값을 12342로 변경하면 ahncoco로 로그인된다. 또한 이런 경우 주요 계정이 초기에 생성되었음을 감안하여 낮은 숫자로 시도함으로 종종 admin 계정과 같은 경우로 로그인 성공하는 경우도 있다.
5.3.3 Cookie Theft와 연계한 사용자 도용
Cookie Theft를 통해 Cookie 정보를 얻어내어야 하는 경우가 있다. 인증에 사용되는 Cookie 정보가 앞선 경우와는 달리 복잡하게 설정된 경우이다. 대표적인 경우는 아래와 같은 경우이다. 아래 정보를 보면 사용자ID, 해당 부서 등의 정보를 얻어내야 할텐데 앞서 논한 단순 사용자 도용과 같이 추측만으로 하기는 어려운 문제이다. 이 경우는 사용자의 Cookie를 얻어내는 방법 즉 Cookie Theft가 필요하다. 하나, 이 경우도 기억할 점이 있다면 Cookie 정보는 많지만 실제 로그인 정보를 유지하고 사용자 정보를 구분하는 핵심 Cookie 정보만 필요하다는 점이다. 그런 정보가 많지 않고 간단하게 구현되어 있다면 그것을 파악하면 좀 더 쉽게 작업을 할 수 있다.
|
ASPSESSIONIDCARTBSDR=CCNGEOOABFJGIHHCJIIEPFBP; LoginInfo=Key=79%1683%1667%1668%1660%1677%16&EditorMode=1&HOST=coconut%2Eonnet21%2Ecom&SvcOrder=5%2CB05%2C0%2C0%2C10%2CB10%2C0%2C0%2C12%2CC02%2C0%2C0%2C14%2CC04%2C0%2C0%2C17%2CC08%2C1%2C1%2C11%2CC01%2C1%2C1%2C7%2CB07%2C1%2C1%2C8%2CB08%2C1%2C1%2C3%2CB03%2C1%2C1%2C2%2CB02%2C1%2C1%2C13%2CC03%2C1%2C1%2C4%2CB04%2C1%2C1%2C9%2CB09%2C1%2C1%2C1%2CB01%2C1%2C0%2C6%2CB06%2C1%2C0%2C&MailHost=mail&EmpID=54&UserID=hosik&PosName=+%B4%EB%B8%AE&ComName=%28%C1%D6%29%BE%C8%B7%A6%C4%DA%C4%DA%B3%D3&bbp=YldWc2IyNW5JUT09&DOMAIN=coconut%2Eonnet21%2Ecom&ComID=COCONUT&DeptName=%BA%B8%BE%C8%B1%E2%BC%FA%BF%AC%B1%B8%C6%C0&UType=N&UpperDepts=i%5FDeptId%3D26+OR+i%5FDeptId%3D22+OR+i%5FDeptId%3D0&fmode=1&Name=%C0%CC%BF%EB%C7%D0&DeptID=26&ID=hosik |
얻어낸 Cookie를 재사용하여 로그인할 수 있는 문제점, 공격 기법을 Cookie Replay라고 부른다.
DB랑 연동을 하다보면 배열의 값을 한 문자로 만들어서 저장해야 하는 경우가 빈번하다.
배열의 인덱스가 100개면 배열의 값을 하나씩 필드 100개를 만들어 저장 할 수도 있지만
모두 미친짓이라고 할것이다.
그래서 대부분 하나의 문자열로 보내서 DB 필드에 저장하고,
다시 그 값을 받을 때 배열로 쪼개야 하기 때문에 중간에 보통 구분자를 넣어서 하나의문자열로 저장을 한다.
다음과 같이 하면
배열 dA는 원래 자기가 처음에 s배열에 저장 했던 내용을 그대로 dA배열에 저장 할 수 있다.
s = [];
s[9] = 9;
sA = s.join("(#)");
sA 로 보내고 아래처럼 받아서 사용한다.
dA = sA.split("(#)");
http://apache-korea.org/tomcat/tomcat-4.1-doc/jndi-datasource-examples-howto.html
dsddJNDI Datasource HOW-TO
| 소개 Introduction |
|
| 데이타베이스 커넥션풀(DBCP) 설정 Database Connection Pool (DBCP) Configurations | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| Tyrex 커넥션 풀 Tyrex Connection Pool | ||||||||||||||||||||||||||||||||||||||||||||||
|
| DBCP를 사용하지 않는 방법들 Non DBCP Solutions |
|
| OCI 클라이언트로 Oracle8i 연결 Oracle 8i with OCI client | |||||||||||||
|
| 일반적으로 일어날 수 있는 문제 Common Problems | ||||
|
vim 으로 파일 한꺼번에 고치기
vi 에는 파일을 오픈한 뒤 특정한 명령을 실행 할 수있는 -c 옵션이 있다.
예를 들어 vi -c 15 foo.c 이렇게 하면 foo.c 를 오픈한 뒤 ':15' 명령을 실행해 15번째 줄로 이동을 한다.
vim 에서는 이 기능을 확장하여 -c 옵션을 여러개 사용할 수 있다.
예를 들어 vim -c '11' -c 'd' foo.c 하면 foo.c 를 열고, 11번째 줄로 이동(-c '11')을 한 다음 현재 라인 지움(-c 'd') 동작을 한다.
여기에 -c 'wq' 를 추가하면 수정후 저장/종료까지 한꺼번에 되므로 command line 명령 처럼 사용할 수 있게 되고, shell script 를 이용해 여러 파일에 적용하면 된다.
예를 들어 현재 디렉토리의 모든 c 소스 에서 'foo' 라는 문자열을 'bar' 로 바꾸고 싶다면
#!/bin/csh -f
foreach fn (*.c)
vim -c '%s/foo/bar/g' -c 'wq' $fn
end
처럼 script를 만들면 된다.
물론 단순 패턴 치환이라면
#!/bin/csh -f
foreach fn (*.c)
sed $fn 's/foo/bar/g' > tmpfile
mv tmpfile $fn
end
와같이 해도 되지만 vim이 할 수 있는 일은 단순 패턴 치환 이상이기 때문에 훨씬 더 다양한 용도로 사용할 수 있다.
아래는 현재 디렉토리와 바로 아래 서브디렉토리의 모든 *.txt 파일을 dos 형식(cr-lf 가 붙는)으로 바꾸는 script 이다.
#!/bin/csh -f
foreach fn ( *.txt */*.txt )
vim -c 'set fileformat=dos' -c 'wq' $fn
end
현재 디렉토리의 모든 *.c *.h 파일로 부터 syntax highlighting 된 html 파일을 만들어 보자.
#!/bin/csh -f
foreach fn ( *.[ch] )
vim -c 'call Convert2HTML(0,0)' -c wq -c q $fn
end
.vimrc 에
set termencoding=euc-kr
set fileencodings=euc-kr,utf-8
.cshrc 에
alias kvi '/usr/bin/vim --cmd "set fileencoding=euc-kr" --cmd "set encoding=euc-kr" \!*'
alias uvi '/usr/bin/vim --cmd "set fileencoding=utf-8" --cmd "set encoding=utf-8" \!*'
이렇게 해두고.. utf-8 파일을 편집 할 때는 uvi를, euc-kr 파일을 편집할 때는 kvi 를 사용하면 된다.
UTF-8 로 저장된 파일을 편집시 : e ++enc=utf-8
euc-kr로 파일을 저장할 때 : w ++enc=euc-kr
<IfModule mod_setenvif.c>
SetEnvIfNoCase Request_URI "\$.(gif)|(jpg)|(css)|(png)" do_not_log
</IfModule>
CustomLog "logs/access_log" common env=!do_not_log
* String 문자 자르기.
---------------------------------------------*/
String.prototype.cut = function(len) {
var str = this;
var l = 0;
for (var i=0; i<str.length; i++) {
l += (str.charCodeAt(i) > 128) ? 2 : 1;
if (l > len) return str.substring(0,i);
}
return str;
}
/*---------------------------------------------
* String 공백 지우기.
---------------------------------------------*/
String.prototype.trim = function(){
// Use a regular expression to replace leading and trailing
// spaces with the empty string
return this.replace(/(^\s*)|(\s*$)/g, "");
}
/*---------------------------------------------
* String 총 바이트 수 구하기.
---------------------------------------------*/
String.prototype.bytes = function() {
var str = this;
var l = 0;
for (var i=0; i<str.length; i++) l += (str.charCodeAt(i) > 128) ? 2 : 1;
return l;
}
/*---------------------------------------------
* iframe의 height를 body의 내용만큼 자동으로 늘려줌.
---------------------------------------------*/
function resizeRetry(){
if(ifrContents.document.body.readyState == "complete"){
clearInterval(ifrContentsTimer);
}
else{
resizeFrame(ifrContents.name);
}
}
var ifrContentsTimer;
var ifrContents;
function resizeFrame(name){
var oBody = document.body;
var oFrame = parent.document.all(name);
ifrContents = oFrame;
var min_height = 613; //iframe의 최소높이(너무 작아지는 걸 막기위함, 픽셀단위, 편집가능)
var min_width = 540; //iframe의 최소너비
var i_height = oBody.scrollHeight + 10;
var i_width = oBody.scrollWidth + (oBody.offsetWidth-oBody.clientWidth);
if(i_height < min_height) i_height = min_height;
if(i_width < min_width) i_width = min_width;
oFrame.style.height = i_height;
ifrContentsTimer = setInterval("resizeRetry()",100);
}
/*---------------------------------------------
* 클립보드에 해당 내용을 복사함.
---------------------------------------------*/
function setClipBoardText(strValue){
window.clipboardData.setData('Text', strValue);
alert("" + strValue +" \n\n위 내용이 복사되었습니다.\n\nCtrl + v 키를 사용하여, 붙여 넣기를 사용하실 수 있습니다.");
}
/*---------------------------------------------
select 에서 기존의 선택 값이 선택되게
----------------------------------------------*/
function selOrign(frm,val){
for(i=0; i < frm.length ; i++){
if(frm.options[i].value == val){
frm.options.selectedIndex = i ;
return;
}
}
}
/*---------------------------------------------
checkbox 에서 기존의 선택 값이 선택되게
----------------------------------------------*/
function chkboxOrign(frm,val){
if(frm.length == null){
if(frm.value == val)
frm.checked = true;
}else{
for(i=0;i<frm.length;i++){
if(frm[i].value == val){
frm[i].checked = true;
}
}
return;
}
}
function chkboxOrign_multi(frm,objchk,val){
var i = 0;
for(i=0;i<frm.elements.length;i++){
if(frm.elements[i].name == objchk){
if(frm.elements[i].value == val){
frm.elements[i].checked = true;
}
}
}
}
/*---------------------------------------------
radio 에서 기존의 선택 값이 선택되게
----------------------------------------------*/
function radioOrign(frm,val){
for(i=0; i < frm.length ; i++){
if(frm[i].value == val){
frm[i].checked = true ;
return ;
}
}
}
/*---------------------------------------------
숫자만 입력받기
예) onKeyDown="return onlyNum();"
----------------------------------------------*/
function onlyNum(){
if(
(event.keyCode >= 48 && event.keyCode <=57) ||
(event.keyCode >= 96 && event.keyCode <=105) ||
(event.keyCode >= 37 && event.keyCode <=40) ||
event.keyCode == 9 ||
event.keyCode == 8 ||
event.keyCode == 46
){
//48-57(0-9)
//96-105(키패드0-9)
//8 : backspace
//46 : delete key
//9 :tab
//37-40 : left, up, right, down
event.returnValue=true;
}
else{
//alert('숫자만 입력 가능합니다.');
event.returnValue=false;
}
}
/*---------------------------------------------
지정된 길이반큼만 입력받기
예) onKeyUp="return checkAllowLength(현재숫자보여지는객체,숫자셀객체 ,80);" onKeyDown="return checkAllowLength(현재숫자보여지는객체,숫자셀객체 ,80);"
----------------------------------------------*/
function checkAllowLength(objView, objTar, max_cnt){
if(event.keyCode > 31 || event.keyCode == "") {
if(objTar.value.bytes() > max_cnt){
alert("최대 " + max_cnt + "byte를 넘길 수 없습니다.");
objTar.value = objTar.value.cut(max_cnt);
}
}
objView.value = objTar.value.bytes();
}
/*--------------------------------------------
이미지 리사이즈
---------------------------------------------*/
function resizeImg(imgObj, max_width, max_height){
var dst_width;
var dst_height;
var img_width;
var img_height;
img_width = parseInt(imgObj.width);
img_height = parseInt(imgObj.height);
if(img_width == 0 || img_height == 0){
imgObj.style.display = '';
return false;
}
// 가로비율 우선으로 시작
if(img_width > max_width || img_height > max_height) {
// 가로기준으로 리사이즈
dst_width = max_width;
dst_height = Math.ceil((max_width / img_width) * img_height);
// 세로가 max_height 를 벗어났을 때
if(dst_height > max_height) {
dst_height = max_height;
dst_width = Math.ceil((max_height / img_height) * img_width);
}
imgObj.width = dst_width;
imgObj.height = dst_height;
}
// 가로비율 우선으로 끝
imgObj.style.display = '';
return true;
}
/*---------------------------------------------
xml data 읽어오기
----------------------------------------------*/
function getXmlHttpRequest(_url, _param){
var objXmlConn;
try{objXmlConn = new ActiveXObject("Msxml2.XMLHTTP.3.0");}
catch(e){try{objXmlConn = new ActiveXObject("Microsoft.XMLHTTP");}catch(oc){objXmlConn = null;}}
if(!objXmlConn && typeof XMLHttpRequest != "undefined") objXmlConn = new XMLHttpRequest();
objXmlConn.open("GET", _url + "?" + _param, false);
objXmlConn.send(null);
//code|message 형태로 리턴
return objXmlConn.responseText.trim().split("|");
}
/*---------------------------------------------------
cookie 설정
-------------------------------------------------------*/
function getCookieVal (offset) {
var endstr = document.cookie.indexOf (";", offset);
if (endstr == -1) endstr = document.cookie.length;
return unescape(document.cookie.substring(offset, endstr));
}
function GetCookie (name) {
var arg = name + "=";
var alen = arg.length;
var clen = document.cookie.length;
var i = 0;
while (i < clen) { //while open
var j = i + alen;
if (document.cookie.substring(i, j) == arg)
return getCookieVal (j);
i = document.cookie.indexOf(" ", i) + 1;
if (i == 0) break;
} //while close
return null;
}
function SetCookie (name, value) {
var argv = SetCookie.arguments;
var argc = SetCookie.arguments.length;
var expires = (2 < argc) ? argv[2] : null;
var path = (3 < argc) ? argv[3] : null;
var domain = (4 < argc) ? argv[4] : null;
var secure = (5 < argc) ? argv[5] : false;
document.cookie = name + "=" + escape (value) +
((expires == null) ? "" :
("; expires=" + expires.toGMTString())) +
((path == null) ? "" : ("; path=" + path)) +
((domain == null) ? "" : ("; domain=" + domain)) +
((secure == true) ? "; secure" : "");
}
/* ---------------------------------------------
* 함수명 : checkSpecialChar
* 설 명 : 특수문자 체크
* 예) if(!checkSpecialChar()) return;
---------------------------------------------*/
function checkSpecialChar(_obj){
if(_obj.value.search(/[\",\',<,>]/g) >= 0) {
alert("문자열에 특수문자( \", ', <, > )가 있습니다.\n특수문자를 제거하여 주십시오!");
_obj.select();
_obj.focus();
}
}
/*
* http://forum.java.sun.com/thread.jspa?threadID=521779&tstart=90
* File name: TestServlet.java
*
* Created on 2005.01.21.
*/
package georgie.test.servlet;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import javax.net.ssl.HostnameVerifier;
import javax.net.ssl.HttpsURLConnection;
import javax.net.ssl.SSLSession;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* @author György Novák
*/
public class TestServlet extends HttpServlet
{
protected void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException
{
try
{
trustAllHttpsCertificates();
String urlStr = request.getParameter("url");
HttpsURLConnection.setDefaultHostnameVerifier(hv);
URL url = new URL(urlStr == null ? "https://www.verisign.com/"
: urlStr);
debug("URL READY");
BufferedReader in = new BufferedReader(new InputStreamReader(url
.openStream()));
debug("INPUT READY");
int buff;
while ((buff = in.read()) != -1)
{
}
in.close();
debug("EVERYTHING IS DONE!!!");
}
catch (Exception e)
{
e.printStackTrace();
}
}
HostnameVerifier hv = new HostnameVerifier()
{
public boolean verify(String urlHostName, SSLSession session)
{
System.out.println("Warning: URL Host: " + urlHostName + " vs. "
+ session.getPeerHost());
return true;
}
};
private void debug(String s)
{
System.out.println("[DEBUG] -- TestServlet -- \n" + s);
}
private static void trustAllHttpsCertificates() throws Exception
{
// Create a trust manager that does not validate certificate chains:
javax.net.ssl.TrustManager[] trustAllCerts =
new javax.net.ssl.TrustManager[1];
javax.net.ssl.TrustManager tm = new miTM();
trustAllCerts[0] = tm;
javax.net.ssl.SSLContext sc =
javax.net.ssl.SSLContext.getInstance("SSL");
sc.init(null, trustAllCerts, null);
javax.net.ssl.HttpsURLConnection.setDefaultSSLSocketFactory(
sc.getSocketFactory());
}
public static class miTM implements javax.net.ssl.TrustManager,
javax.net.ssl.X509TrustManager
{
public java.security.cert.X509Certificate[] getAcceptedIssuers()
{
return null;
}
public boolean isServerTrusted(
java.security.cert.X509Certificate[] certs)
{
return true;
}
public boolean isClientTrusted(
java.security.cert.X509Certificate[] certs)
{
return true;
}
public void checkServerTrusted(
java.security.cert.X509Certificate[] certs, String authType)
throws java.security.cert.CertificateException
{
return;
}
public void checkClientTrusted(
java.security.cert.X509Certificate[] certs, String authType)
throws java.security.cert.CertificateException
{
return;
}
}
}
インターネットバンキングやネットショッピングなどのように、インターネットを通じてWebブラウザから操作する仕組みを使って金融取引や通信販売などのサービスを提供する場合、第三者による不正行為を防止するために、利用者とサービス提供者以外に対して情報が漏洩することを防ぐ必要がある。
そこで現在、一般的に採用されている方法が、SSLによる暗号化通信機能を付加したHTTPによる通信である。SSL通信やHTTPS通信と呼ばれることが多く、実質的に業界標準といえる。JavaもHTTPS通信に対応しており、HTTPSによって提供されているサイトにアクセスすることができる。
URLConnection - HTTPS通信にも対応
アクセス先はURIで保持しておき、使う段階でURLに変換して使う。そして実際の通信はURLConnectionを経由して実施する。これはHTTPプログラミングを実施する際の基本だ。これについては第54回「HTTP通信の基礎(1) - URIとURL、URLConnection」で説明した。
同回において、実際にURLConnectionを使ってアクセスし、ヘッダとコンテンツを取得するソースコードを紹介した。同ソースコードを使ってHTTPSでサービスを提供しているサイトのコンテンツを取得させてみてほしい。
リスト1 NetCat.java
import java.net.*;
import java.util.*;
public class NetCat {
public static void main(String[] argv)
throws Exception {
URI uri = new URI(argv[0]);
URLConnection connection = uri.toURL().openConnection();
// ヘッダ情報を出力
Map headers = connection.getHeaderFields();
for (Object key : headers.keySet()) {
System.out.println(key + ": " + headers.get(key));
}
// コンテンツを出力
BufferedReader reader =
new BufferedReader(new InputStreamReader
(connection.getInputStream(), "JISAutoDetect"));
String buffer = reader.readLine();
System.out.println();
while (null != buffer) {
System.out.println(buffer);
buffer = reader.readLine();
}
}
}
プロンプト1 NetCat.java を使ってHTTPS通信で提供されているサイトにアクセス
Connection: [close]
Date: [Mon, 24 Jul 2006 04:07:53 GMT]
null: [HTTP/1.1 200 OK]
Pragma: [no-cache]
Server: [Apache]
Content-Type: [text/html; charset=EUC-JP]
Transfer-Encoding: [chunked]
Cache-Control: [no-cache]
Vary: [Accept-Encoding]
<html>
<head>
...
%
プロンプト1が実行例だ。HTTPSでサービスが提供されているサイトも、HTTPの場合と同じように表示されていることがわかる。URLConnectionは抽象クラスであり、実際にはHttpURLConnectionやHttpsURLConnection、JarURLConnectionなどのサブクラスを経由して使うことになる。つまり、ただ単に通信を実施してコンテンツのやりとりをおこなう程度であれば、URLConnectionを使っておけばよいことがわかる。
HTTPSに特化した処理は HttpsURLConnection を使う
HTTPSに特化した処理はURLConnectionではなく、HttpsURLConnectionを使う。HttpsURLConnectionはHttpURLConnectionを継承したクラスであるため、HTTPと共通の機能はHttpURLConnectionを使えばよく、SSL特有の処理が必要な場合にだけHttpsURLConnectionを使えばいい。HttpsURLConnectionを使った例をリスト2に示す。URLConnectionインスタンスをHttpsURLConnectionインスタンスにキャストして使っていることがわかるだろう。HTTPSで通信を実施した場合、実体はHttpsURLConnectionだからキャストが可能だ。
リスト2 SSLNetCat.java
import java.net.*;
import java.util.*;
import javax.net.ssl.*;
public class SSLNetCat {
public static void main(String[] argv)
throws Exception {
URI uri = new URI(argv[0]);
URLConnection connection = uri.toURL().openConnection();
// ヘッダ情報を出力
Map headers = connection.getHeaderFields();
for (Object key : headers.keySet()) {
System.out.println(key + ": " + headers.get(key));
}
// SSL情報を出力
HttpsURLConnection sslconnection =
(HttpsURLConnection)connection;
System.out.println();
System.out.println("符号化方式:" + sslconnection.getCipherSuite());
// コンテンツを出力
BufferedReader reader =
new BufferedReader(new InputStreamReader
(connection.getInputStream(), "JISAutoDetect"));
String buffer = reader.readLine();
System.out.println();
while (null != buffer) {
System.out.println(buffer);
buffer = reader.readLine();
}
}
}
プロンプト2 SSLNetCat.java を使ってHTTPS通信で提供されているサイトにアクセス
Connection: [close]
Date: [Mon, 24 Jul 2006 04:30:09 GMT]
null: [HTTP/1.1 200 OK]
Pragma: [no-cache]
Server: [Apache]
Content-Type: [text/html; charset=EUC-JP]
Transfer-Encoding: [chunked]
Cache-Control: [no-cache]
Vary: [Accept-Encoding]
符号化方式:SSL_RSA_WITH_RC4_128_MD5
<html>
<head>
...
% l
ためしにリスト2をHTTPS通信ではないサイトの通信に適用してみるといい。キャストに失敗して処理が終了する。HTTPS通信でない場合はHttpsURLConnectionへはキャストできない。
HttpsURLConnection
HttpsURLConnectionにはほかにもハンドシェーク中にサーバとやりとりした証明書や、セッションを定義する段階における主体などを得るためのメソッドも用意されている。接続先の制御や細かい制御をおこないたい場合は、これらメソッドを通じて情報を取得することになる。
HttpsURLConnectionを使わなくとも、URLConnectionを使っていればHTTP/HTTPSの両方が同じように扱える点は、Java APIの便利なところといえるだろう。ちなみにHttpsURLConnectionはjava.netパッケージではなく、javax.net.sslパッケージにまとめられている。importを忘れないようにしたい。
이제는 VIM 을 기본 문서 편집기로 연결해놓고 있다.
C/C++ 의 소스편집과 분석은 물론이고, 일반 문서 편집에도 최고이다.
거기다가 OS 를 가리지 않는 범용성.
사용하는 동안 써본 최고의 플러그인들을 모아봤다.
사실 이미 오래전부터 올리려고 했던 파일 모음인데,
이제야 올리게 되었다. 거의 1년 가까운 시간이 지난 지금.
그래서 현재 최신버전은 VIM6.4 이지만 설명이 6.3을 기준으로 되어있다.
모든 플러그인들은 물론 6.4에서도 잘 동작한다.
하지만 오래전 작성된 관계로 플러그인들이 최신으로 갱신되었을 가능성이 있다.
플러그인 모음 파일의 구성은 다음과 같다.
1. 설치
- 설명 파일 및 다큐멘트
Readme1st.txt
그외 rtf 파일은 짬짬이 기록해놓은 VIM 툴 팁이다.
(rtf 파일은 기본적으로는 워드에 연결되어 있지만, 워드패드에서 열수 있고,
훈민메모패드에서도 불러들일 수 있다. 훈민메모패드 최고 ! )
- vimrc 초기화 파일 :
gvimrc_silver.com
$VIM (vim을 설치한 루트 디렉토리)/_vimrc 에서 "gvimrc-silver.vim" 을 부르도록 수정 필요.
- tools for vim
다음의 툴들을 %PATH%
ec55w32 : Exuberant Ctags 5.5
태그 파일을 만들어 주는 프로그램. "taglist.vim" 플러그인에서 사용한다.
gvimrc_silver.com 의 키맵 <F7> , <F8>, <F9> 를 사용해서 작업한다.
cscope : 태그에서 한발 나아간 관계형 DB작성 프로그램,
소스인사이트 처럼 심볼 찾기, 함수 Caller/Callee 를 찾을 수 있다.
자세한 사용법은 나중에 다시 설명 예정.
참조 Vim Cscope Tutorial (http://wiki.kldp.org/wiki.php/VimCscopeTutorial)
- Plugin FIles
$VIMRUNTIME (vim 실행 파일이 위치한 디렉토리) [ = $VIM (vim을 설치한 루트 디렉토리)/vim버전]
필요한 경우 해당 폴더의 백업을 해도 좋다.
해당 위치에 파일을 풀어주면 된다.
즉 Tools\Vim Essential Addon 을 $VIMRUNTIME 에다가 덮어주면 된다.
- Plugin help file add
설치한 플러그인 파일의 도움말에 대한 태그를 생성한다.
:helptags $VIMRUNTIME/doc
( 설치후 ":help winmanager" 혹은 ":help tag" 입력후 CTRL-D를 입력해본다.)
2. 사용법
먼저 VIM 에서 멀티 윈도우기능을 사용하기 위해서는
":help windows" 를 실행하여 "window.txt" 의 키 이해필요.
멀티 윈도우에서의 기본기능은 하나의 윈도우에서 의 전후좌우 (h, j, k, l)에
CTRL_W 를 앞에 먼저 입력하면 윈도우 간의 이동이 가능하다.
예 ::: CTRL-W ( <C-W> ) + h : 좌 윈도우
그외 자세하고 세부적인 사항은 역시 써봐야 한다.
VIM은 쓰면 쓸 수록 그 놀라운 기능과 다양한 지원에 놀라게 된다.
- <F6>
토글 키 ,
윈도우매니저 기능 On/Off
파일을 연상태에서 <F6> 을 누르면 왼쪽 상단 에 [File List] 하단에 [Buf List] 가 생성됨.
[File List] 를 이용해서 특정 폴더로 이동 , 파일을 열수 있음.
*** 이때 현재 디렉토리 위치는 변경되지 않음. (":pwd" 로 확인)
디렉토리 위치의 이동을 위해서는 명령창에서 cd 실행.
[Buf List] VIM 버퍼에 있는 파일의 리스트를 보여줌, 선택하여 열기 가능.
- <F7>,<F8>,<F9>
토글 키
<F8> : 태그리스트 On/Off
<F7> : 태그 갱신 (즉 파일내용이 바뀌었을 때 사용)
<F9> : 태그 리스트의 싱크 (코드와 태그의 상태를 맞춰줌)
[Tag List] 가 좌측에 새김 ( 매크로, 변수, 함수 등이 표시됨.)
[출처] http://blog.naver.com/agfe2/90002349695
java를 처음 공부하면서 초반에 컴파일 및 실행을 시키기해서 cmd창을 자주 쓰게 된다
탐색기에 익숙한 우리들에게 cmd창에서 폴더 이동은 어지간 짜증나는 일이 아닐수 없다.
간단한 레지스트리 추가로 원하는 폴더에서 바로 cmd창을 열어보자...
============================================================
실행 ==> regedit
레스지트 창을 연다
HKEY_CLASSESS_ROOT
|
+-- directory
|
+-- shell
로 이동한다
새로만들기 => key를 실행하다
임의의 폴더이름을 만들고, 폴더안에 기본값에 데이터를 "도스창 바로가기" 등의 메뉴 이름을 정한다
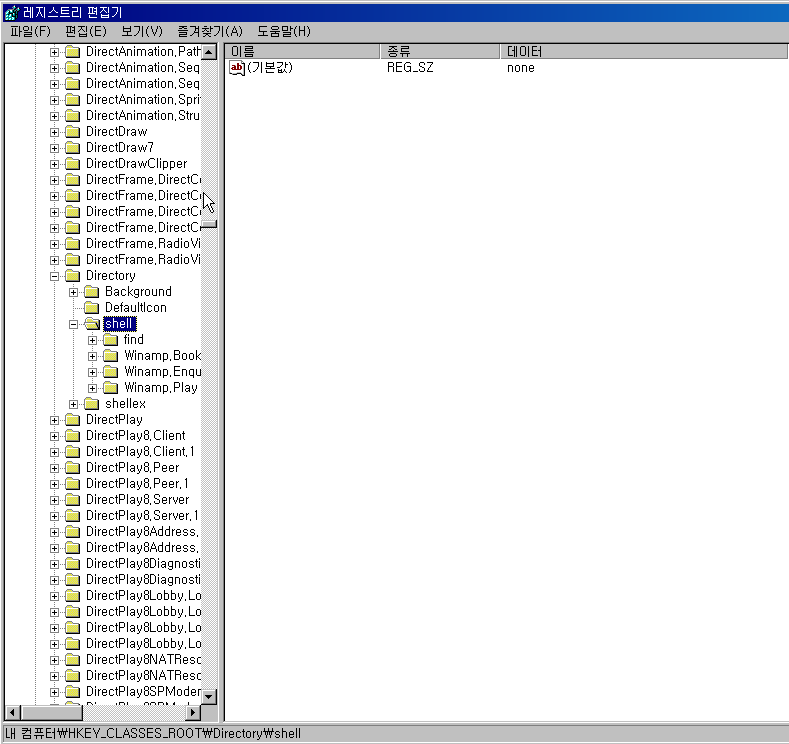
만든 폴더안에 다시 한번
새로만들기 => key를 실행한다
폴더이름은 command로 하고 기본키의 데이터값을
C:\WINDOWS\system32\cmd.exe /k cd "%1"
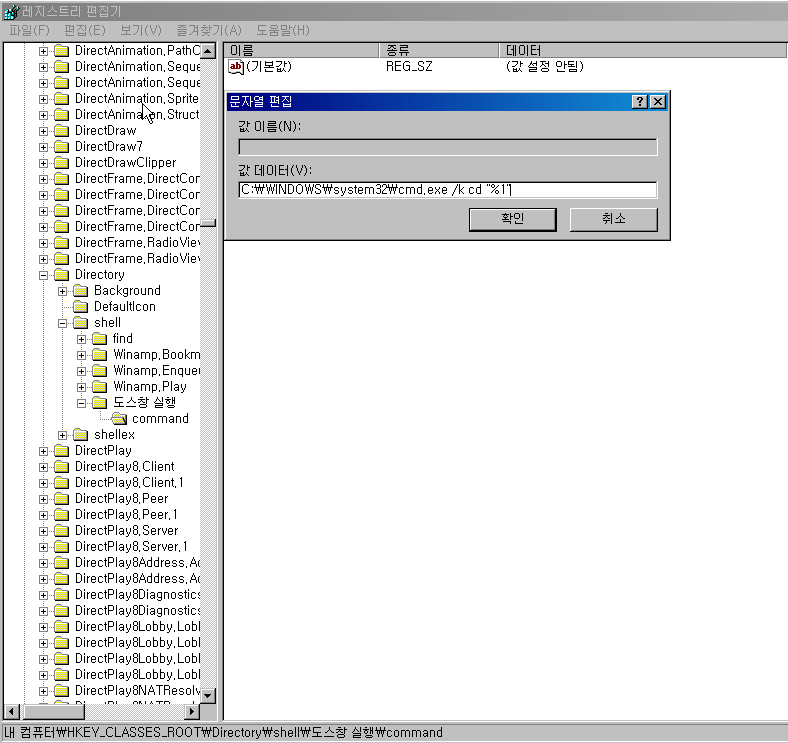
이제부터 탐색기에서 원하는 폴더에 우측 버튼을 열리면 "도스창 바로가기" 가 생겨 바로 선택한 폴더에서 cmd창이 열리는 것을 볼수 있다
개발자가 놓치기 쉬운 자바의 기본원리
- 전성호(커뮤니티본부 커뮤니티개발1팀), 2006년 10월
목차
-
- 1 객체지향의 구멍 static
- 2 Java는 Pointer언어이다? (Java에는 Pointer밖에 없다?)
- 3 상속과 interface의 문제점
- 4 package와 access 제어에 관한 이해
- 5 기타 Java 기능
- 6 이래도 Java가 간단한가?
- 7 Java 기능 적용 몇가지
- 8 Java 5.0 Tiger 에 대하여
-
- 8.1 Working with java.util.Arrays
- 8.2 Using java.util.Queue interface
- 8.3 java.lang.StringBuilder 사용하기
- 8.4 Using Type-Safe Lists
- 8.5 Writing Generic Types
- 8.6 새로운 static final enum
- 8.7 Using java.util.EnumMap
- 8.8 Using java.util.EnumSet
- 8.9 Convert Primitives to Wrapper Types
- 8.10 Method Overload resolution in AutoBoxing
- 8.11 가변적인 argument 개수 ...
- 8.12 The Three Standard Annotation
- 8.13 Creating Custom Annotation Types
- 8.2 Using java.util.Queue interface
- 8.1 Working with java.util.Arrays
- 9 The for/in Statement
-
- 9.1 for/in 의 자주 사용되는 형태
- 10 Static Import
-
- 10.1 static member/method import
- 11 References
1.1 Java는 객체지향 언어이다? #
- 오해1. "객체지향에서는 객체끼리 서로 메세지를 주고 받으며 동작한다." 라는 말을 듣고 다음과 같이 생각할 수 있다. "객체지향에서는 객체가 각각 독립하여 움직인다는 것인가, 그러면 각 객체에 독립된 thread가 할당되어 있단 말인가?" 그렇지 않다. "메세지를 보낸다"라는 것은 단순히 각 객체의 함수 호출에 불과하다.
- 오해2. "객체지향에서는 method가 class에 부속되어 있다"는 말을 듣고 다음과 같이 생각할 수 있다. "그러면 instance별로 method의 실행코드가 복제되고 있는 것이 아닌가?" 물론 이것도 오해다. method의 실행코드는 종래의 함수와 동일한 어딘가 다른곳(JVM의 class area)에 존재하며 그 첫번째 파라미터로 객체의 포인터 this가 건네질 뿐이다.
- 오해3. "그렇다면 각 instance가 method의 실행코드를 통째로 갖고 있지 않는 것은 확실하지만, method의 실행 코드의 포인터는 각 instance별로 보관하고 있는것이 아닌가?" 이것은 약가 애매한 오해이긴 하다. JVM 스펙에서는 class영역에 실행코드를 갖고 있으며, method 호출시 별도의 stack frame이 생성되어 실행되고 실행 완료시 복귀 주소를 전달한다.
1.2 전역변수 #
- (참고) final 초기화에서의 주의점. 예를 들어 다음과 같은 코드를 보았을때 우려되는 점은 무엇인가?
public final static Color WHITE = new Color(255, 255, 255);
- static field는 final의 경우와 달리 정말 "하나여도 되는지" 여부를 잘 생각해야 한다.
- static method는 주저하지 말고 쓰되 다음 두가지의 경우 매우 활용적이다.
- 다른 많은 클래스에서 사용하는 Utility Method 군을 만드는 경우. (주로 Utility Class의 method)
- 클래스 안에서만 사용하는 "하청 메소드(private method)". 이유를 예를 들어 설명하면, 아래와 같은 조금은 과장된 클래스가 있다고 하자.
public class T .. private int a; private int b; private int c; private int calc(){ c = a + b; return c * c; } ....other method or getter/setter... private static int calc(int a, int b){ int c = a + b; return c * c; } 2.1 Java는 primitive형을 제외하곤 모두 Pointer이다 #
2.2 null은 객체인가? #
- null object의 instance method 호출
- null object의 field(member variables)에 대한 액세스 또는 그 값의 변경
- null의 길이를 배열처럼 취득할 경우
- null의 slot을 배열처럼 액세스 또는 수정
- null을 Throwable처럼 throw 할 경우
2.3 String에 대하여 #
String str = "111222"; String a = "111"; String b = "222"; String c = "111"; String d = b; String t = str.substring(0,3); //111
- str == (a + b) ==> 이것은 두개의 참조와 하나의 참조를 비교했으므로 당연히 false이다.
- a == b ==> 이것은 당연히 false
- d == b ==> 이것은 동일한 reference이므로 true
- a == t ==> a 와 t 는 둘다 값이 "111"이다. 하지만 이것은 서로 다른 참조를 가져 false이다. 그렇다면 다음 5번도 false일까?
- a == c ==> 이것은 true이다. 아.. 4번과 혼란스럽다. 이것이 참인 이유는? ==> 이것의 해답은 JSR 3.10.5에 다음과 같이 나와 있기 때문이다.
2.4 객체지향의 캡슐화 파괴 주의 #
//(참고)Member에는 두개의 field(Identity Class 형의 ID와 Family Class 형의 family)가 있다. /** shallow copy */ Member shallowCopy(){ Member newer = new Member(); newer.id = this.id; newer.family = this.family; return newer; } /** deep copy */ Member deepCopy(){ Member newer = new Member(); newer.id = new Idetity(this.id.getId(), this.id.getName()); newer.family = new Family(this.family.getFamilyName(), this.family.getFamilyInfo()); return newer; } - 모든 field(member variable)를 생성자(constructor)를 이용하여 초기화 한다.
- 모든 field는 private으로 선언하고, getter method는 만들되 setter는 기술하지 않는다.
2.5.1 배열은 object 인가? #
2.5.2 배열의 length는 왜 field(member variable)인가? #
2.5.3 final과 배열에 대하여... #
2.5.4 "Java에서의 다차원 배열은 존재하지 않는다." #
2.6.1 "Java에서 parameter(argument) 전달은 무조건 'call by value' 이다" #
2.6.2 "C와 같은 언어는 static linking이지만, Java는 dynamic linking이다." #
2.7.1 "Garbage Collection은 만능이 아니다." #
2.8.1 "결국 Java에는 pointer가 있는 것인가, 없는 것인가?" #
// 이부분에 대해 Object를 이해하시면 족히 이런 문제는 사라질것으로 봅니다.
// 클래스에 대한 인스턴스(object)들은 reference로 밖에 가질(참조될)수 없기 때문입니다.
// 컴파일러 입장이 아닌 언어 자체의 사상을 가지고 쉽게 이해시키는 것이 좋을것 같습니다.
3.1.1 상속에 있어서의 생성자(constructor) #
3.1.2 "down cast는 본질적으로 매우 위험하다" #
3.1.3 "추상클래스에 final이 있으면 compile error이다" #
3.2.1 "interface는 interface일뿐 다중 상속의 대용품이 아니다." #
3.3 상속 제대로 사용하기 #
- 상속에서는 슈퍼클래스가 허용하고 있는 조작을 서브클래스에서 모두 허용해야 하지만, composition과 delegation에서는 조작을 제한할 수 있다.
- 클래스는 결코 변경할 수 없지만, composition하고 있는 객체는 자유롭게 변경할 수 있다. 예를 들면 학생 클래스가 영원이 학생이 아니라 나중에 취직을 하여 직장인 클래스가 될수 있다.
- Shape(부모)의 공통된 내용을 구현한 구현 클래스(ShapeImpl)를 만든다.
- Polyline과 Circle 클래스에서 ShapeImpl을 composition하고 부모와 공통되지 않는 method를 각각 위임 받는다.
- ShapeImpl 클래스의 method를 추출한 ShapeIF interface를 작성하고 Polyline과 Circle에서는 implements 한다.
4.1.1 "package는 '계층구조' 인가?" #
4.1.2 "compiler 가 인식하는 class검색 순서(소스코드내 클래스가 발견될 경우 그 클래스의 위치를 찾는 순서)" #
- 그 class자신
- 단일형식으로 임포트된 class
- 동일한 패키지에 존재하는 다른 class
- 온디멘드 형식(..* 형태) 임포트 선언된 class
4.2.1 "interfacde member의 access 제어" #
4.2.2 그렇다면 interface를 다른 package에 대하여 숨기고 싶으면 어떻게 하는가? #
5.1.1 "Multi Thread에서는 흐름은 복수이지만 data는 공유될 수 있다." #
5.1.2 "Thread는 객체와 직교하는 개념이다." #
- Multi Thread에서는 Thread라는 처리 흐름이 2개 이상 존재할 수 있다.
- 어떤 Thread에서 움직이기 시작한 method가 다른 method를 호출 했을때 호출된 측의 method는 호출한 측의 method와 동일한 Thread에서 동작한다.
- Thread의 경계와 객체의 경계는 전혀 관계가 없다. 즉, Thread와 객체는 직교하고 있다.
5.1.3 "Synchronized 의 이해" #
synchronized void method1(){ ... } void method2(){ synchronized(this){ ... } } 5.1.4 "Thread 사용법의 정석은?" #
- Runnable을 implements하고 Thread의 참조를 보유(composition) 하는 방법. 이경우는 단지 Runnable만 implement함으로서 해결되는 경우가 대부분이긴 하지만, 그 class 내에서 해당 class의 Thread를 조작하게 된다면 composition한 Thread 객체에 delegation하면 된기 때문이다.
- Thread class를 상속하는 방법. JDK의 소스를 보면 Thread class에는 Runnable을 implements 하고 있다. 그리고 run method는 native method이다. 따라서 Thread를 상속한 모든 클래스는 사실 Runnable을 implements하고 있는 것이다. run method는 abstract가 아니므로 구현되어 있고 우리는 이를 오버라이드하여 사용하고 있다. 이 방식을 사용하면 Thread의 method를 안팍으로 자유롭게 호출할 수 이지만, 이미 다른 class를 상속하고 있다면 이 방식을 사용할 수는 없다.
5.2.1 "finally 절은 반드시 어떠한 경우에도 실행되는가?" #
try{ ... System.exit(1); }catch(...){ }finally{ ... //이 부분은 실행되지 않는다. }
5.2.2.1 Error #
5.2.2.2 RuntimeException #
5.2.2.3 그밖의 Exception #
5.2.3 "OutOfMemoryError는 어떻게 처리해야 하는가?" #
5.3 Object Serialize #
5.3.1 "Serialize를 위해서는 marker interface인 java.io.Serializable interface를 implements해야한다." #
5.3.2 "super class는 Serializable이 아닌데 sub class만 Serializable인 경우의 문제점" #
5.3.3 "transient field의 복원(?)관련" #
private void writeObject(java.io.ObjectOutputStream out) throws IOException; private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException;
5.3.4 "Stack Overflow에 주의하라!" #
private synchronized void writeObject(java.io.ObjectOutputStream s) throws IOException { s.defaultWrtieObject(); //이 코드는 무조건 들어가게 되는데 이곳 소스의 System.arraycopy()에서 overflow발생한다. s.writeInt(size); //이부분이 실제 추가되어 Stack Overflow를 예방한다. for(Entry e = ...) s.writeObject(e.element); } ... } //readObject()도 이와 같은 개념으로 변경되어 있다. 5.4.1 "중첩클래스의 개념" #
5.4.2 "내부클래스는 부모의 참조를 몰래 보유하고 있다." #
class Test{ class InnerClass { int i; ... } public static void main(String[] args){ InnerClass icls = new InnerClass(); ... } } 5.4.3 "local inner class에 대하여" #
public class OuterClass { public int get(){ int i = 9; int id = 99; int id2 = 99; final int id3 = 100000; class LocalInnerClass { int id = 100; LocalInnerClass(){ System.out.println("LocalInnerClass"); } int getId(){ return id3 + id; } } LocalInnerClass lic = new LocalInnerClass(); return id + lic.getId(); } public static void main(String[] args){ OuterClass outer = new OuterClass(); System.out.println("id = " + outer.get()); //결과 값은 "100000(id3) + 100(LocalInnerClass.id) + 99(OuterClass.get())" 인 100199가 나온다. } } 5.4.4 "anonymous class(무명클래스)에 대하여" #
class AnonymousTest { private interface Printable { void print(); } static void doPrint(Printable p){ p.print(); } public static void main(String[] args){ doPrint( new Printable(){ public void print(){ System.out.println("this is new Printable print()"); } }); } } 6.1.1 "overload란 이름이 가고 인수가 다른 method에 compiler가 다른 이름을 붙이는 기능" #
//IFS.java interface IFS { public String getName(); } //Impl1.java class Impl1 implements IFS { public String getName(){ return "Impl1"; } } //Impl2.java class Impl2 implements IFS { public String getName(){ return "Impl2"; } } //main이 있는 OverloadTest.java public class OverloadTest { static void pr(int i){ System.out.println("pr_int : " + i); } static void pr(String s){ System.out.println("pr_string : " + s); } static void pr(IFS ifs){ System.out.println("pr_string : " + ifs.getName()); } static void pr_run(Impl1 i1){ System.out.println("pr_run : " + i1.getName()); } static void pr_run(Impl2 i2){ System.out.println("pr_run : " + i2.getName()); } public static void main(String[] args){ OverloadTest test = new OverloadTest(); test.pr(10); test.pr("Jeid"); IFS ifs1 = new Impl1(); test.pr(ifs1); IFS ifs2 = new Impl2(); test.pr(ifs2); //pr_run(ifs1); //pr_run(ifs2); } } OverloadTest.java:36: cannot resolve symbol symbol : method pr_run (IFS) location: class OverloadTest pr_run(ifs1); ^ OverloadTest.java:37: cannot resolve symbol symbol : method pr_run (IFS) location: class OverloadTest pr_run(ifs2); ^ 2 errors
6.1.2 "그렇다면 overload에서 실제로 혼동되는 부분은 무엇인가?" #
class OverloadTest2 { static int base(double a, double b){ ... } //method A static int count(int a, int b){ ... } //method B static int count(double a, double b){ ... } //method C static int sum(int a, double b){ ... } //method D static int sum(double a, int b){ ... } //method E } - base(3,4) 를 호출했을때 수행되는 method는? => 당연히 method A (3과 4는 정수라도 double이 되므로 정상적으로 수행됨)
- count(3,4) 를 호출했을때 수행되는 method는? => B와 C중 갈등이 생긴다. 이럴경우 JVM은 가장 한정적(more specific)한 method를 찾는다. 여기서 3과 4는 정수형에 가까우므로 method B 가 호출된다.
- count(3, 4.0) 을 호출했을때 수행되는 method는? => 이것은 4.0 이 double이므로 method C 가 더 한정적이므로 method C 가 호출된다.
- sum(3,4.0) 을 호출했을때 수행되는 method는? => 이것은 당연히 type이 일치하는 method D.
- sum(3,4) 를 호출했을때 수행되는 method는?? => 이런 코드가 소스내에 있으면 다음과 같은 compile 오류를 표출한다.
OverloadTest.java:48: reference to sum is ambiguous, both method sum(int,double) in OverloadTest and method sum(double,int) in OverloadTest match System.out.println("sum(3,4) = " + sum(3,4)); ^ 1 error 6.1.3 (참고) 또다른 혼동, overload한 method를 override 하면? #
6.2.1 "Java class의 member 4 종류" #
- instance field
- instance method
- static field
- static method
6.2.2 "override시 method 이름에 대한 함정" #
6.2.3 "또다른 나의(?) 실수 - 말도 안되는 오타" #
public class Member { private int memberNo; public int getMemberNo(){ return this.memberNo; } public void setMemberNo(int menberNo){ this.memberNo = memberNo; } ...... } 6.2.4 "static member를 instance를 경유하여 참조해서는 안 된다." #
ClassA a = new ClassA(); int i = a.AA; //instance를 경유하여 접근 int j = ClassA.AA; //올바르게 접근
6.2.5 "super keyword는 부모의 this" #
6.4.1 "생성자에 void 를 붙인다면?" #
public class ConstructorTest{ void ConstructorTest(){ System.out.println("Constuctor"); } ..... } 6.4.2 "if / switch 의 함정" #
.... if( a < 5 ) b = 3; c = 10; //이부분은 나중에 추가된 라인이다. if( isStudent ) if( isFemale ) sayHello("Hi~~"); else sayHello("Hello Professor~"); 7.1.1 "interface 분리의 필요성" #
7.2 Java에서의 열거형 #
public static final int LEFT = 0; public static final int CENTER = 1; public static final int RIGHT = 2; ... label.setAlignment(Label.CENTER); ...
//LabelAlignment.java public class LabelAlignment { private LabelAlignment() {} //이는 생성자를 private으로 하여 다른데서는 만들지 못하도록 하기위함이다. public static final LabelAlignment LEFT = new LabelAlignment(): public static final LabelAlignment CENTER = new LabelAlignment(): public static final LabelAlignment RIGHT = new LabelAlignment(): } //변형된 Label.java 의 일부.. public synchronized void setAlignment(LabelAlignment alignment){ if( alignment == LabelAlignment.LEFT ){ ...//왼쪽으로 맞추기.. }else if( ... ... } } ... //LabelAlignment.java public class LabelAlignment { private int flag; private LabelAlignment(int flag){ this.flag = flag; } public static final LabelAlignment LEFT = new LabelAlignment(0): public static final LabelAlignment CENTER = new LabelAlignment(1): public static final LabelAlignment RIGHT = new LabelAlignment(2): public boolean equals(Object obj){ return ((LabelAlignment)obj).flag == this.flag; } } //변형된 Label.java 의 일부.. public synchronized void setAlignment(LabelAlignment alignment){ if( LabelAlignment.LEFT.equals(alignment) ){ ...//왼쪽으로 맞추기.. }else if( ... ... } } ... 7.3 Debug write #
#ifdef DEBUG fprintf(stderr, "error...%d\n", error); #endif /* DEBUG */
if( Debug.isDebug ){ System.out.println("error..." + error); } // 1. GetCallerSecurityManager.java public final class GetCallerSecurityManager extends SecurityManager { public Class[] getStackTrace(){ return this.getClassContext(); } } // 2. GetCallerClass.java public final class GetCallerClass { private static GetCallerSecurityManager mgr; static{ mgr = new GetCallerSecurityManager(); System.setSecurityManager(mgr); } public static void writeCaller(String str){ Class[] stk = mgr.getStackTrace(); int size = stk.length; for(int i = 0; i < size; i++){ System.out.println("stk[" + i + "] = " + stk[i]); } String className = stk[2].getName(); System.out.println("className is " + className + " : " + str); } } // 3. GetCallerClassMain1 : 호출하는 클래스 예제 1 public class GetCallerClassMain1 { public static void main(String[] args){ GetCallerClass.writeCaller(", real is 1."); } } // 4. GetCallerClassMain1 : 호출하는 클래스 예제 2 public class GetCallerClassMain2 { public static void main(String[] args){ GetCallerClass.writeCaller(", real is 2."); } } className is GetCallerClassMain1 : , real is 1. className is GetCallerClassMain2 : , real is 2.
8.1 Working with java.util.Arrays #
package com.jeid.tiger; import java.util.Arrays; import java.util.Comparator; import java.util.List; public class ArraysTester { private int[] arr; private String[] strs; public ArraysTester(int size) { arr = new int[size]; strs = new String[size]; for (int i = 0; i < size; i++) { if (i < 10) { arr[i] = 100 + i; } else if (i < 20) { arr[i] = 1000 - i; } else { arr[i] = i; } strs[i] = "str" + arr[i]; } } public int[] getArr() { return this.arr; } public String[] getStrs() { return this.strs; } public static void main(String[] args) { int size = 50; ArraysTester tester = new ArraysTester(size); int[] testerArr = tester.getArr(); int[] cloneArr = tester.getArr().clone(); String[] testerStrs = tester.getStrs(); String[] cloneStrs = tester.getStrs().clone(); // clone test if (Arrays.equals(cloneArr, testerArr)) { System.out.println("clonse int array is same."); } else { System.out.println("clonse int array is NOT same."); } if (Arrays.equals(cloneStrs, testerStrs)) { System.out.println("clonse String array is same."); } else { System.out.println("clonse String array is NOT same."); } // 2부터 10까지 값 셋팅 Arrays.fill(cloneArr, 2, 10, new Double(Math.PI).intValue()); testerArr[10] = 98; testerStrs[10] = "corea"; testerStrs[11] = null; List<String> listTest = Arrays.asList(testerStrs); System.out.println("listTest[10] = " + listTest.get(10)); System.out.println("------- unsorted arr -------"); System.out.println("Arrays.toString(int[]) = " + Arrays.toString(testerArr)); System.out.println("Arrays.toString(String[]) = " + Arrays.toString(testerStrs)); Arrays.sort(testerArr); // Arrays.sort(testerStrs); //NullPointerException in sort method..(null이 없더라도 길이에 대한 크기 체크는 못함) Arrays.sort(testerStrs, new Comparator<String>() { public int compare(String s1, String s2) { if (s1 == null && s2 == null) { return 0; } else if (s1 == null && s2 != null) { return -1; } else if (s1 != null && s2 == null) { return 1; } else if (s1.length() < s2.length()) { return -1; } else if (s1.length() > s2.length()) { return 1; } else if (s1.length() == s2.length()) { return 0; } else { return s1.compareTo(s2); } } }); System.out.println("------- sorted arr -------"); System.out.println("Arrays.toString(int[]) = " + Arrays.toString(testerArr)); System.out.println("Arrays.toString(String[]) = " + Arrays.toString(testerStrs)); System.out.println("------------------------------------------------"); String[][] mstrs1 = { { "A", "B" }, { "C", "D" } }; String[][] mstrs2 = { { "a", "b" }, { "c", "d" } }; String[][] mstrs3 = { { "A", "B" }, { "C", "D" } }; System.out.println("Arrays.deepToString(mstrs1) = " + Arrays.deepToString(mstrs1)); System.out.println("Arrays.deepToString(mstrs2) = " + Arrays.deepToString(mstrs2)); System.out.println("Arrays.deepToString(mstrs3) = " + Arrays.deepToString(mstrs3)); if( Arrays.deepEquals(mstrs1, mstrs2)) { System.out.println("mstrs1 is same the mstrs2."); }else { System.out.println("mstrs1 is NOT same the mstrs2."); } if( Arrays.deepEquals(mstrs1, mstrs3)) { System.out.println("mstrs1 is same the mstrs3."); }else { System.out.println("mstrs1 is NOT same the mstrs3."); } System.out.println("mstrs1's hashCode = " + Arrays.deepHashCode(mstrs1)); System.out.println("mstrs2's hashCode = " + Arrays.deepHashCode(mstrs2)); System.out.println("mstrs3's hashCode = " + Arrays.deepHashCode(mstrs3)); } } 8.2 Using java.util.Queue interface #
package com.jeid.tiger; import java.util.LinkedList; import java.util.PriorityQueue; import java.util.Queue; public class QueueTester { public static void main(String[] args) { System.out.println("---------- testFIFO ----------"); testFIFO(); System.out.println("---------- testOrdering ----------"); testOrdering(); } private static void testFIFO() { Queue<String> q = new LinkedList<String>(); q.add("First"); q.add("Second"); q.add("Third"); String str; while ((str = q.poll()) != null) { System.out.println(str); } } private static void testOrdering() { int size = 10; Queue<Integer> qi = new PriorityQueue<Integer>(size); Queue<String> qs = new PriorityQueue<String>(size); for (int i = 0; i < size; i++) { qi.offer(10 - i); qs.offer("str" + (10 - i)); } for (int i = 0; i < size; i++) { System.out.println("qi[" + i + "] = " + qi.poll() + ", qs[" + i + "] = " + qs.poll()); } } } 8.3 java.lang.StringBuilder 사용하기 #
package com.jeid.tiger; import java.util.ArrayList; import java.util.Iterator; import java.util.List; public class StringBuilderTester { public static void main(String[] args) { List<String> list = new ArrayList<String>(); list.add("str1"); list.add("str2"); list.add("str3"); String ret = appendItems(list); System.out.println("ret = " + ret); } private static String appendItems(List<String> list) { StringBuilder sb = new StringBuilder(); for (Iterator<String> iter = list.iterator(); iter.hasNext();) { sb.append(iter.next()).append(" "); } return sb.toString(); } } 8.4 Using Type-Safe Lists #
package com.jeid.tiger; import java.util.Iterator; import java.util.LinkedList; import java.util.List; public class ListTester { public static void main(String[] args) { List<String> list = new LinkedList<String>(); list.add("str1"); list.add("str2"); list.add(new Integer(123)); // <-- String이 아니므로 compile error!! //Iterator에 String type을 명시하므로 정삭작동됨. for (Iterator<String> iter = list.iterator(); iter.hasNext();) { String str = iter.next(); System.out.println("srt = " + str); } //Iterator에 String type을 명시하지 않았으므로 아래 A 부분에서 compile 오류 발생!! for (Iterator iter = list.iterator(); iter.hasNext();) { String str = iter.next(); //A System.out.println("srt = " + str); } //byte, short, int, long, double, float 동시 사용 List<Number> lstNum = new LinkedList<Number>(); lstNum.add(1); lstNum.add(1.2); for (Iterator<Number> iter = lstNum.iterator(); iter.hasNext();) { Number num = iter.next(); System.out.println("num = " + num); } } } 8.5 Writing Generic Types #
class AnyTypeList<T> { //class AnyTypeList<T extends Number> { // <-- 이는 Number를 상속한 type은 허용하겠다는 의미. private List<T> list; //private static List<T> list; // <-- 이는 정적이므로 compile error 발생!!! public AnyTypeList(){ list = new LinkedList<T>(); } public boolean isEmpty(){ return list == null || list.size() == 0; } public void add(T t){ list.add(t); } public T grap(){ if (!isEmpty() ) { return list.get(0); } else { return null; } } } 8.6 새로운 static final enum #
package com.jeid.tiger; import com.jeid.BaseObject; import com.jeid.MyLevel; public class EnumTester extends BaseObject { private static long start = System.currentTimeMillis(); public static void main(String[] args) { try { test(); enum1(); } catch (Exception e) { e.printStackTrace(); } printEllapseTime(); } private static void test() throws Exception { byte[] b = new byte[0]; System.out.println(b.length); } private static void enum1() { //enum TestEnum { A, B }; //enum cannot be local!!! for(MyVO.TestEnum te: MyVO.TestEnum.values()){ System.out.println("Allow TestEnum value : " + te); } System.out.println("---------------------------------------"); MyVO vo = new MyVO(); vo.setName("enum1"); vo.setLevel(MyLevel.A); System.out.println(vo); System.out.println("isA = " + vo.isA() + ", isGradeA = " + vo.isLevelA()+ ", isValueOfA = " + vo.isValueOfA()); System.out.println("getLevelInKorean = " + vo.getLevelInKorean()); } private static void printEllapseTime() { System.out.println("==> ellapseTime is " + (System.currentTimeMillis() - start) + " ms."); } } package com.jeid.tiger; import com.jeid.BaseObject; import com.jeid.MyLevel; public class MyVO extends BaseObject { enum TestEnum { A, B }; // this is same public static final private int id; private String name; private MyLevel grade; // private List<T> list; public MyLevel getLevel() { return grade; } public void setLevel(MyLevel grade) { this.grade = grade; } public boolean isA() { return "A".equals(this.grade); } public boolean isValueOfA() { return MyLevel.valueOf("A").equals(grade); } public boolean isLevelA() { return MyLevel.A.equals(this.grade); } //A,B,C..대신 0,1,2... 도 동일함. public String getLevelInKorean() { switch(this.grade){ case A: return "수"; case B: return "우"; case C: return "미"; case D: return "양"; case E: return "가"; default: return "없음"; } } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } } 8.7 Using java.util.EnumMap #
package com.jeid.tiger; import java.util.EnumMap; public class EnumMapTester { private enum MyEnum { A, B, C }; // this is same the static final.. public static void main(String[] args) { MyEnum[] enums = MyEnum.values(); System.out.println("MyEnum is " + enums[0] + ", " + enums[1] + ", " + enums[2]); EnumMap<MyEnum, String> em = new EnumMap<MyEnum, String>(MyEnum.class); em.put(MyEnum.A, "수"); em.put(MyEnum.B, "우"); em.put(MyEnum.C, "미"); em.put(MyEnum.B, "가"); //key 중복은 HashMap과 동일하게 overwrite임. for (MyEnum myEnum : MyEnum.values()) { System.out.println(myEnum + " => " + em.get(myEnum)); } } } 8.8 Using java.util.EnumSet #
package com.jeid.tiger; import java.util.EnumSet; public class EnumSetTester { private enum MyEnum { A, B, C, a, b, c }; // this is same the static final.. public static void main(String[] args) { MyEnum[] enums = MyEnum.values(); System.out.println("MyEnum is " + enums[0] + ", " + enums[1] + ", " + enums[2]); EnumSet<MyEnum> es1 = EnumSet.of(MyEnum.A, MyEnum.B, MyEnum.C); EnumSet<MyEnum> es2 = EnumSet.of(MyEnum.a, MyEnum.b, MyEnum.c); EnumSet<MyEnum> es3 = EnumSet.range(MyEnum.a, MyEnum.c); if (es2.equals(es3)) { System.out.println("e2 is same e3."); } for (MyEnum myEnum : MyEnum.values()) { System.out.println(myEnum + " contains => " + es1.contains(myEnum)); } } } 8.9 Convert Primitives to Wrapper Types #
package com.jeid.tiger; public class AutoBoxingTester { public static void main(String[] args) { int i = 0; Integer ii = i; // boxing. JDK 1.4에서는 incompatible type error가 발생 했었으나 Tiger에서는 괜찮다. int j = ii; // unboxing for (ii = 0; ii < 5; ii++) { // Integer인데도 ++ 연산자 지원. } i = 129; ii = 129; if (ii == i) { System.out.println("i is same ii."); } // -128 ~ 127 사이의 수는 unboxing이 되어 == 연산이 허용되지만, // 그 범위 외의 경우 Integer로 boxing된 상태므로 equals를 이용해야함. // 이는 버그가 발생했을 경우 찾기 쉽지 않은 단점도 내포하고 있다.!! checkIntegerSame(127, 127); // same checkIntegerSame(128, 128); // Not same checkIntegerEquals(128, 128); // equals checkIntegerSame(-128, -128); // same checkIntegerSame(-129, -129); // Not same checkIntegerEquals(-129, -129); // equals System.out.println("--------------------------------------------"); Boolean arriving = false; Boolean late = true; String ret = arriving ? (late ? "도착했지만 늦었네요." : "제시간에 잘 도착했군요.") : (late ? "도착도 못하고 늦었군요." : "도착은 못했지만 늦진 않았군요."); System.out.println(ret); StringBuilder sb = new StringBuilder(); sb.append("appended String"); String str = "just String"; boolean mutable = true; CharSequence chSeq = mutable ? sb : str; System.out.println(chSeq); } private static void checkIntegerSame(Integer ii, Integer jj) { if (ii == jj) { System.out.println("ii = " + ii + ", jj = " + jj + " ==> jj is same ii."); } else { System.out.println("ii = " + ii + ", jj = " + jj + " ==> jj is NOT same ii!!"); } } private static void checkIntegerEquals(Integer ii, Integer jj) { if (ii.equals(jj)) { System.out.println("ii = " + ii + ", jj = " + jj + " ==> jj is equals ii."); } else { System.out.println("ii = " + ii + ", jj = " + jj + " ==> jj is NOT equals ii!!"); } } } 8.10 Method Overload resolution in AutoBoxing #
package com.jeid.tiger; public class OverloadTester { public static void main(String[] args) { double d = 10; Integer ii = new Integer(10); doSomething(10); doSomething(1000); doSomething(ii); doSomething(d); } private static void doSomething(Integer ii) { System.out.println("This is doSomething(Integer)"); } private static void doSomething(double d) { System.out.println("This is doSomething(double)"); } } 8.11 가변적인 argument 개수 ... #
package com.jeid.tiger; public class VarArgsTester { public static void main(String[] args) { setNumbers(1, 2); setNumbers(1, 2, 3, 4); setNumbers(1); // setNumbers(); //해당 되는 method가 없어 compile error!! System.out.println("=============================================="); setNumbers2(1, 2, 3, 4); setNumbers2(1); setNumbers2(); } // this is same setNumbers(int first, int[] others) private static void setNumbers(int first, int... others) { System.out.println("-----------setNumbers()----------- : " + first); for (int i : others) { System.out.println("i = " + i); } } // this is same setNumbers(int[] others) private static void setNumbers2(int... others) { System.out.println("-----------setNumbers2()----------- : " + (others != null && others.length > 0 ? others[0] : "null")); for (int i : others) { System.out.println("i = " + i); } } } 8.12 The Three Standard Annotation #
//정상적인 사용 @Override public int hashCode(){ return toString().hashCode(); } //스펠링이 틀려 compile error!! @Override public int hasCode(){ //misspelled => method does not override a method from its superclass error!! return toString().hashCode(); } package com.jeid.tiger; public class AnnotationDeprecateTester { public static void main(String[] args){ DeprecatedClass dep = new DeprecatedTester(); dep.doSomething(10); //deprecated } } class DeprecatedClass { @Deprecated public void doSomething(int ii){ //deprecated System.out.println("This is DeprecatedClass's doSomething(int)"); } public void doSomethingElse(int ii){ System.out.println("This is DeprecatedClass's doSomethingElse(int)"); } } class DeprecatedTester extends DeprecatedClass { @Override public void doSomething(int ii){ System.out.println("This is DeprecatedTester's doSomething(int)"); } } package com.jeid.tiger; import java.util.ArrayList; import java.util.List; public class AnnotationSuppressWarningsTester { @SuppressWarnings({"unchecked", "fallthrough"} ) private static void test1(){ List list = new ArrayList(); list.add("aaaaaa"); } @SuppressWarnings("unchecked") private static void test2(){ List list = new ArrayList(); list.add("aaaaaa"); } //warning이 없는 소스. private static void test3(){ List<String> list = new ArrayList<String>(); list.add("aaaaaa"); } } 8.13 Creating Custom Annotation Types #
package com.jeid.tiger; import java.lang.annotation.Documented; import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; @Documented @Target( { ElementType.TYPE, ElementType.FIELD, ElementType.METHOD, ElementType.ANNOTATION_TYPE }) @Retention(RetentionPolicy.RUNTIME) public @interface MyAnnotation { String columnName(); String methodName() default ""; } //사용하는 쪽.. public class AnnotationTester { @MyAnnotation(columnName = "test", methodName = "setTest") private String test; @MyAnnotation(columnName = "grpid") public String grpid; .... } //위의 test 멤버의 경우 다음과 같이 접근 가능하다. Field testField = cls.getDeclaredField("test"); if (testField.isAnnotationPresent(MyAnnotation.class)) { Annotatioin anno = testField.getAnnotation(MyAnnotation.class); System.out.println(anno.columnName() + ", method = " + anno.methodName()); } 9.1 for/in 의 자주 사용되는 형태 #
//1. 가장 단순한 형태인 배열(array) String[] strs = { "aaa", "bbb", "ccc" }; for (String str : strs) { System.out.println(str); } //2. List by using Iterator List<Number> lstNum = new LinkedList<Number>(); lstNum.add(1); lstNum.add(1.2); for (Iterator<Number> iter = lstNum.iterator(); iter.hasNext();) { Number num = iter.next(); System.out.println("num = " + num); } //3. List를 바로 사용 List<String> lst = new LinkedList<String>(); lst.add("aaaaa"); lst.add("bbbbb"); lst.add("ccccc"); lst.add("ddddd"); for (String str : lst) { System.out.println("str = " + str); } // 4. List of List List[] lists = { lst, lst }; for (List<String> l : lists) { for (String str : l) { System.out.println("str = " + str); } } 10.1 static member/method import #
//예를 들어 System.out.println() 이라는 것을 사용하기 위해서는 다음의 import 문이 필요하다. import java.lang.System; //물론 java.lang 이기에 import 문이 필요없지만 예를 들자면 그렇다는 것이다.&^^ //허나, Tiger에서는 다음과 같이 사용할수 있다. import static java.lang.System.out; ... out.println(...); // method를 import 한다면.. import static java.lang.System.out.println; ... println(...);
11 References #
- http://java.sun.com/j2se/1.4.2/docs/index.html
- http://java.sun.com/j2se/1.5.0/docs/index.html
- SUN의 JLS
- http://java.sun.com/docs/books/jls/html/index.html
- Java 핵심원리 - 마에바시 가즈야 저 - 영진닷컴
- Java 1.5 Tiger - Brett McLaughlin 저 - O'Reilly
출처: http://dna.daum.net/technote/java/PrincipleOfJavaInternalForDeveloperEasyToLost
 invalid-file
invalid-file invalid-file
invalid-file
| ||||||||||||||||
|
1. 텔넷 프로토콜 텔넷은 인터넷 사의 다른 컴퓨터로 로그인을 할 수 있게 하는 프로토콜이다. 2. 텔넷 명령어 텔넷 프로토콜은 서버와 클라이언트 서로를 제어하기 위하여 많은 명령어를 사용한다. 이러한 명령어는 IAC(interpret as command)문자 다음에 보내진다.
3. 텔넷 옵션 또한 여러 가지 상태를 설정하기 위한 옵션이 있다. 이 옵션들은 언제든지 재설정될 수 있으며, 서버나 클라이언트 어느 쪽에서도 설정할 수 있다. 옵션의 정확한 스펙은 각각의 rpc를 참고 하여야 한다.
옵션은 클라이언트나 서버 어느 한쪽에서 요구를 하여, 다른 한 쪽에서 그것에 응답하는 형태로 설정된다. 옵션을 요구할 때는
의 차례로 코드를 보내며, 응답 또한 같은 방식이다.
WILL이나 WONT는 옵션을 요구하는 쪽이 그 옵션을 사용 또는 사용하지 않겠다는 뜻이며, DO나 DONT는 상대방측에 옵션을 사용 또는 사용하지 말라고 요구하는 것이다. 한쪽에서 요구를 하면 상대방은 응답을 해야 한다. 요구와 응답의 조합은 다음의 경우만이 가능하다.
SB명령어는 하나 이상의 옵션을 필요로 할 때 사용된다. 터미널 타입이나, 터미널의 크기 등을 보내고 받는데 사용된다. 텔넷 클라이언트로 텔넷의 옵션 협상 과정을 살펴보자.
4. 텔넷 클라이언트 프로그램의 소스는 프로토콜을 처리하는 protocal.c와 그 외의 모든 함수가 포함된 telnet 텔넷 클라이언트가 해야 할 일은 기본적으로 다음과 같다. -서버로의 stream socket 연결을 한다. 소켓 연결 및 초기 설정 서버와 소켓을 연결하는 과정은 다른 stream socket을 이용하는 프로그램과 별차이점이 없 소스의 main()에서 불리어지는 init_system()함수를 살펴보자. -소켓에 read()를 호출했는데 읽을 데이터가 없을 때. 이 외에도 많은 경우가 있지만 이 프로그램에서는 위의 경우에 블록이 일어난다. 블록이 일어나면 프로세서는 블록이 해제될 때까지 멈추어 진다.
소켓의 연결이 끊겼을 때에는 read()가 0을 리턴하고 또한 write()가 SIGPIPE 시그널을 발생한다. SIGPIPE 시그널을 가로챔으로서 소켓 연결이 끊겼을 때를 알 수 있다.
SIGPIPE 시그널은 peer_died()함수에 연결되었다. Peer_died()함수는 상대방의 연결이 끊겼을 때의 각종 처리를 수행한다. 그러므로, 소켓의 연결이 끊어져서 write()가 SIGPIPE 시그널을 발생시키면 peer_died()함수가 실행된다. main_loop() main-loop() 함수는 텔넷 클라이언트의 일반적인 작업을 수행한다. 하나의 무한루프인 이 함수는 소켓과 데이터의 입출력, 그것의 프로토콜 처리 그리고 키보드로부터의 입력을 처리하는 과정을 반복해서 처리한다.
우리가 소켓에 쓸 데이터는 먼저 write_buf에 저장된다. 이 데이터는 main_loop()에서 select()시스템 호출로 소켓에 데이터를 쓸 수 있다는 것이 확인된 뒤에야 write_socket()함수를 통해서 실제로 전송이 된다. 소켓으로 읽은 데이터는 읽을 데이터가 있을 때에만 read_socket()을 통해서, 모두 read_buf에 저장된다. read_buf에 저장된 데이터는 프로토콜 처리를 위하여 process_protocol() 함수에서 읽혀진다. 표3은 이러한 데이터의 처리 과정을 도식적으로 그린 것이다.
<표3 데이터 처리과정> 버퍼 처리 함수 텔넷 프로토콜을 처리하는 과정에서 우리는 서버쪽으로 프로토콜을 보낼 수도 있어야 하고, 소켓에서 읽혀진 데이터를 파싱하여 프로토콜 처리를 할 때에는 read_buf에서 하나씩 문자를 읽어서 필요한 프로토콜 부분을 추출해야 한다. putc_socket()과 puts_socket()은 write_buf에 데이터를 집어넣는 함수이다. 이러한 편의함수들은 전부 프로토콜을 처리하는 과정에서 필요한 함수들이다. 텔넷 프로토콜 파싱 process_protocol()은 read_buf에 저장된 데이터를 파싱하여 텔넷 프로토콜을 처리한다. 이
여기서 TELCMDS, TELOPTS를 #include 앞에서 정의한 이유는 telnet.h에 있는 텔넷 명령어 테이블인 telcmds와, 텔넷 옵션 테이블인 telopts를 사용하기 위해서이다. 텔넷 옵션 처리 process_option()은 IAC+[DO|DONT|WILL|WONT]으로 시작되는 옵션을 처리하는 함수이다. 옵션을 처리하는데 있어서 가장 어려운 점은 텔넷 옵션 협상 과정이 대칭적이란 점이다. 즉 똑 같은 옵션을 받을 수 있고, 보낼 수도 있어야 한다는 점이다. 이럴 때는 서버로부터 받은 옵션이 우리가 보낸 옵션의 응답인지 아니면 요구를 하는 명령인지를 구분하기가 어렵다. 이 처리를 하기 위해서 option[]배열을 만들었다. options[]의 각각의 필드는 해당 옵션에 대해 요구를 했는지의 여부를 저장한다. option_requested()는 해당 옵션이 요구되었는지 여부를 판단한다. 이것이 '참'을 리턴하면 해당 옵션이 요구되었다는 것을 의미한다. 이 함수를 이용하여 우리가 옵션을 서버에 보낼 때에는 option_requestd()를 호출하여 옵션 요구 상태를 설정하고, 옵션을 서버로부터 받을 때에는 그것이 요구인지 응답인지의 여부를 option_requested()를 호출함으로써 판단한다. 옵션 협상 과정을 통해 처리된 옵션이 저장되어야 할 경우에는 이 정보를 mode에 저장한다. ECHO의 여부(MODE_ECHO)나 바이너리 모드인지의 여부 (MODE_INBIN, MODE_OUTBIN) 등이 이러한 정보다. Mode를 다루는 함수는 mode_set() 이다. 가공 모드에 대한 정의는 arpa/telnet.h에 포함되어 있다. 우리가 다루는 모드는 모두 set_terminal()에서 처리된다. 텔넷 프로토콜의 정의에 따르면 텔넷 클라이언트는 모든 텔넷 옵션을 처리할 수 있어야 한다고 되어 있다. 우리가 지원하지 않는 옵션이라도 서버가 요구하면 응답할 수 있어야 한다. Option_ok()는 옵션이 현재 지원되는지 여부를 판단한다. TELOPT_BINARY 옵션은 8비트 데이터의 처리 여부를 결정하는 옵션이다. 서버가 WILL 또는 WONT로 요구했을 경우에는 서버가 8 비트 데이터를 처리할지 여부를 말하는 것이므로, 우리는 MODE_INBIN 즉 8비트를 받아들이겠다는 모드를 설정해야 한다. TELOPT_BINARY가 DO 또는 DONT를 요구한다면 이는 클라이언트의 8비트 처리 여부이크로, 틀라이언트가 8비트를 출력하겠다는 MODE_OUTBIN을 설정해야 한다. TELOPT_ECHO는 터미널이 키보드로부터의 입력을 ECHO해야 하는지를 설정한다. 서버가 ECHO를 하겠다면 컬라이언트는 ECHO를 하지 말아야하고, 서버가 ECHO를 하지 않겠다면 클라이언트는 ECHO를 해야한다. Network Virtual Terminal 텔넷 프로토콜은 Network Virtual Terminal(NVT)를 포함한다. 클라이언트는 서버로부터 받은 NVT코드를 화면 처리를 위한 적절한 코드로 바꾸어야 하고, 사용자 키보드로부터 받은 입력을 NVT코드로 바꾸어야 한다. 이것은 CR/NL 맵팅, 탭의 처리 등을 포함한다. 우리의 프로그램은 이러한 처리를 set_terminal()에서 터미널 세팅을 통해서 행한다. 그러나 이것은 NVT를 완벽히 지원하지 않는다. 다만 간단히 하기 위한 해킹이다. 프로그램 종료 함수 프로그램을 끝내는 함수로는 peer_died(), do_bye(), sys_error()가 있다. -close()로 소켓을 닫는다. Set_terminal()에서 터미널을 항상 raw 모드로 만든다(완전한 raw 모드는 아니다). 그래서 사용자의 키보드 인터럽트 등이 동작하지 않는다. 우리가 escape character를 지원하지 않기 때문에 현재 do_bye()를 통해 사용자가 프로그램을 강제 종료 시킬 수는 없다. 5. 간단한 텔넷 클라이언트의 소스 텔넷의 옵션은 많고도 아주 복잡하다. 이러한 처리를 모두 지원하기 위해서는 프로그램이 상당히 복잡해진다. 여기서는 간단히 필요한 몇 개의 옵션만 지원하며, 알고리즘도 간단하게 하여 완전한 텔넷 스펙을 지원하지 않는다.
7.마치면서 이 프로그램은 실제적인 어플리케이션에서 쓰이기에는 너무나 버그가 많고, 프로토콜 지원이 빈약하다. 그러나 텔넷 클라이언트 프로그래밍을 이해하기에는 충분하리라 생각된다. 다음 편에서는 소켓을 서버 프로그램의 입장에서 다루어 본다.
출처 telnet client 프로그램의 구현|작성자 돌마루 |