http://ericmiraglia.com/blog/?p=140
Transcript:
Douglas Crockford: Welcome. I’m Doug Crockford of Yahoo! and today we’re going to talk about Ajax performance. It’s a pretty dry topic — it’s sort of a heavy topic — so we’ll ease into it by first talking about a much lighter subject: brain damage. How many of you have seen the film Memento? Brilliant film, highly recommend it. If you haven’t seen it, go get it and watch it on DVD a couple of times. The protagonist is Leonard Shelby, and he had an injury to his head which caused some pretty significant brain damage — particular damage as he is unable to form new memories. So he is constantly having to remind himself what the context of his life is, and so he keeps a large set of notes and photographs and even tattoos, which are constant reminds to him as to what the state of the world is. But it takes a long time for him to sort through that stuff and try to rediscover his current context, and so he’s constantly reintroducing himself to people, starting over, making bad decisions around the people he’s interacting with, because he really doesn’t know what’s going on around him.
If Leonard were a computer, he would be a Web Server. Because Web Servers work pretty much the same way. They have no short term memory which goes from one context to another — they’re constantly starting over, sending stuff back to the database, having to recover every time someone ‘talks’ to them. So having a conversation with such a thing has a lot of inefficiencies built into it. But the inefficiencies we’re going to talk about today are more related to what happens on the browser side of that conversation, rather than on the server.
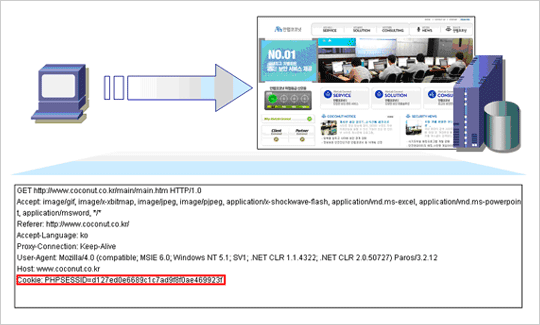
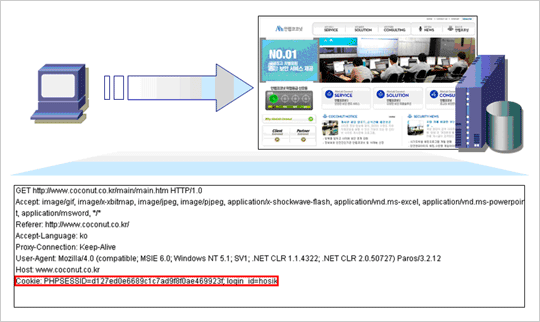
So the web was intended to be sessionless, because being sessionless is easier to scale. But it turns out, our applications are mainly session full, and so we have to make sessions work on the sessionless technology. We use cookies for pseudosessions, so that we can correlate what would otherwise be unconnected events, and turn them into a stream of events — which would look more like a session. Unfortunately cookies enable cross site scripting or cross site request forge attacks, so it’s not a perfect solution. Also in the model, every action results in a page replacement, which is costly, because pages are heavy, complicated, multi-part things, and assembling one of those, and getting it across the wire can take a lot of time. And that definitely gets in the way of interactivity. So the web is a big step backwards in interactivity — but fortunately we can get most of that interactive potential back.
“When your only tool is a hammer, every problem looks like a webpage.” This is an adage you may have heard before — this is becoming less true because of Ajax. In the Ajax revolution, a page is an application which has a data connection to a server, and is able to update itself over time, avoiding a page replacement. So when the user does something, we send a JSON message to the server, and we can receive a JSON message as the result.
A JSON message is less work for the server to generate, it moves much faster on the wire because it’s smaller, it’s less work for the browser to parse and render than an HTML document. So, a lot of efficiencies are gained here. Here’s a time map of a web application. We start with the server on this side [motions left], the browser on the other [motions right], time running down. The first event is the browser makes a request — probably a URL or a GET Request — going to the server. The server respond with an HTML payload, which might actually be in multiple parts because it’s got images, and scripts, and a lot of other stuff in it. And it’s a much bigger thing than the GET request, so it takes lots of packets. It can take a significant amount of time. And Steve Souders has talked a lot about the things that we can do to reduce this time. The user then looks at the page for a moment, clicks on something, which will cause another request — and in the conventional web architecture, the response is another page. And this is a fairly slow cycle.
Now in Ajax — we start the same, so the page is still the way we deliver the application. But now when the user clicks on something, we’ll generate a request for some JSON data, which is about the same size as the former GET request, but the response is now much smaller. And we can do a lot of these now —so instead of the occasional big page replacement, we can have a lot of these little data replacements, or data updates, happening. So it is significantly more responsive than the old method.
One of the difficult things in designing such an application is getting the division of labour right: how should the application be divided between the browser and the server? This is something most of us don’t have much good experience with, and so that leads us to the pendulum of despair. In the first stage of the swing, everything happened on the server — the server looked on the browser as being a terminal. So all of the work is going on here, and we just saw the inefficiencies that come from that. When Ajax happened, we saw the pendulum swing to the other side — so everything’s happening on the browser now, with the view now that the server is just a file system.
I think the right place is some happy middle — so, we need to seek the middle way. And I think of that middle way as a pleasant dialogue between specialized peers. Neither is responsible for the entire application, but each is very competent at its specialty.
So when we Ajaxify an application, the client and the server are in a dialog, and we make the messages between them be as small as possible — I think that’s one of the key indications if you’re doing your protocol design properly. If your messages tend to be huge because, say, you’re trying to replicate the database, the browser — then I would say you’re not in the middle, you’re still way off to one end. The browser doesn’t need a copy of the database. It just needs, at any moment, just enough information that the user needs to see at that moment. So don’t try to rewrite the entire application in JavaScript — I think that’s not an effective way to use the browser. For one reason: the browser was not intended to do any of this stuff — and as you’ve all experienced, it doesn’t do any of this stuff very well. The browser is a very inefficient application platform, and if your application becomes bloated, performance can become very bad. So you need to try to keep the client programming as light as possible, to get as much of the functionality as you need, without making the application itself overly complex, which is a difficult thing to do.
Amazingly, the browser works, but it doesn’t work very well — it’s a very difficult platform to work with. There are significant security problems, there are significant performance problems. It simply wasn’t designed to be an application delivery system. But it got enough stuff right, perhaps by accident or perhaps by clever design, that we’re able to get a lot of the stuff done with it anyway. But it’s difficult doing Ajax in the browser because Ajax pushes the browser really hard — and as we’ll see, sometimes the browser will push back.
But before thinking about performance, I think absolutely the first thing you have to worry about is correctness. Don’t worry about optimization until you have the application working correctly. If it isn’t right, it doesn’t matter if it’s fast. But that said, test for performance as early as possible — don’t wait until you’re about to ship to decide to test to see if it’s going to be fast or not. You want to get the bad news as early in the development cycle as possible. And test in customer—like configurations — customers will have slow network connections, they’ll have slow computers. Testing on the developmer box on the local network to a developer server is probably not going to be a good test of your application. It’s really easy for the high performance of the local configuration to mask your sensitivity to latency problems.
Donald Knuth of Stanford said that “premature optimization is the root of all evil,” and by that he means ‘don’t start optimizing until you know that you need to.’ So, one place that you obviously know you need optimizing is in the start up — getting the initial page load in. And the work we’ve done here on exceptional performances is absolutely the right stuff to be looking at in order to reduce the latency of the page start up. So don’t optimize until you need to, but find out as early as possible if you do need to. Keep your code clean and correct, because clean code is much easier to optimize than sloppy code. So starting from a correct base, you’ll have a much easier time. Tweaking, I’ve found, for performance, is generally ineffective, and should be avoided. It is not effective, and I’ll show you some examples of that. Sometimes restructuring or redesign is required — that’s something we don’t like to do, because it’s hard and expensive. But sometimes that’s the only thing that works.
So let me give you an example of refactoring. Here’s a simple Fibonacci function. Fibonacci is a function for a value whose function is the sum of the two previous values, and this is a very classic way of writing it. Unfortunately, this recursive definition has some performance problems. So if I ask for the 40th Fibonacci number, it will end up calling itself over 300,000 times — or, 300,000,000 times. No matter how you try to optimize this loop, having to deal with a number that big, you’re not ever going to get it to a satisfactory level of performance. So here I can’t fiddle with the code to make it go faster — I’m going to have to do some major restructuring.
So one approach to restructuring would be to put in a memoizer — similar idea to caching, where I will remember every value that the thing created, and if I ever am asked to produce something for the same parameter, I can return the thing from the look up, rather than having to recompute it. So, here’s a function which does that. I pass it an array of values, and a fundamental function, it will return a function which when called, will look to see if it already knows the answer. And so it will return it, and if not, it will call itself, and pass its shell into that function, so that it can recurs on it. So using that, I can then plug in a simple definition of Fibonacci, here — and when I call Fibonacci on 40, it ends up calling itself 38 times. And it has kind of been doing a little bit more work in those 38 times, than it did on each individual iteration before, but we’ve got a huge reduction in the number — an optimization of about 10 million, which is significant. And that’s much better than you’re ever going to do by tweaking and fiddling. So sometimes you just have to change your algorithm.
So, getting back to the code quality. High quality code is most likely to avoid platform problems, and I recommend the Code Conventions for JavaScript Programming Language, which you can find at http://javascript.crockford.com/code.html. I also highly recommend that you use JSLint.com on all of your code. Your code should be going through without warnings — that will increase the likelihood that it’s going to work on all platforms. It’s not a guarantee, but it is a benefit. And it can catch a large class of errors that are difficult to catch otherwise. Also to improve your code quality, I recommend that you have regular code readings. Don’t wait until you’re about to release to read through the code — I recommend every week, get the whole team sitting at a table, looking at your stuff. It’s a really, really good use of your time. Experienced developers can lead by example, showing the others how stuff’s done. Novice developers can learn very quickly from the group, problems can be discovered early — you don’t have to wait until integration to find out if something’s gone wrong. And best of all — good techniques can be shared early. It’s a really good educational process.
If you finally decide you have to optimize, there are generally two ways you can think about optimizing JavaScript. There’s streamlining, which can be characterized by algorithm replacement, or work avoidance, or code removal. Sometimes we think of productivity in terms of the number of lines of code that we produce in a day, but any day when I can reduce the number of lines of code in my project, I think of that as a good day. The metrics of programming are radically different than any other human activity, where we should be rewarded for doing less, but that’s how programming works. So, these are always good things to do, and you don’t even necessarily need to wait for a performance problem to show up to consider doing these things. The other kind of optimization would be special casing. I don’t like adding special cases, I’ve tried to avoid it as much as possible — they add cruft to the code, they increase code size, increase the number of paths that you need to test. They increase the number of places you need to change when something needs to be updated, they significantly increase the likelihood that you’re going to add errors to the code. They should only be done when it’s proven to be absolutely necessary.
I recommend avoiding unnecessary displays or animation. When Ajax first occurred, we saw a lot of ‘wow’ demonstrations, like ‘wow, I didn’t know a browser could do that’ and you see things chasing around the screen, or chasing, or opening, or doing that stuff [gestures]. There are a lot of project managers, and project flippingss, who look at that stuff not understanding how those applications are supposed to deliver value — they get on that stuff instead, because it’s shiny and… But I recommend avoiding it. ‘Wow’ has a cost, and in particular as we’re looking more at widgeting as the model for application development, as we have more and more widgets, if they’re all spinning around on the screen, consuming resources, they’re going to interfere with each other and degrade the performance of the whole application. So I recommend making every widget as efficient as possible. A ‘wow’ effect is definitely worthwhile if it improves the user’s productivity, or improves the value of the experience to user. If it’s there just to show that we can do that, I think it’s a waste of our time, it’s a waste of the user’s time.
So when you’re looking at what to optimize, only speed up things that take a lot of time. If you speed up the things that don’t take up much time, you’re not going to yield much of an improvement. Here’s a map of some time — we’ve got an application which we can structure, the time spent on this application into four major pieces. If we work really hard and optimize the C code [gestures to shortest block] so that it’s using only half the time that it is now, the result is not going to be significant. Whereas if we could invest less but get a 10% improvement on the A code [gestures to longest block] that’s going to have a much bigger impact. So it doesn’t do any good to optimize that [gesture to block C], this is the big opportunity, this is the one to look at [gestures to block A].
Now, it turns out, in the browser, there’s a really big disparity in the amount of time that JavaScript itself takes. If JavaScript were infinitely fast, most pages would run at about the same speed — I’ll show you the evidence of that in a moment. The bottleneck tends to be the DOM interface — DOM is a really inefficient API. There’s a significant cost every time you touch the DOM, and each touch can result in a reflow computation, which can be very expensive. So touch the DOM lightly, if you can. It’s faster to manipulate new nodes before they are attached to the tree — once they’re attached to the tree, any manipulating of those nodes can result in another repaint. Touching unattached nodes avoids a lot of the reflow cost. Setting innerHTML does an enormous amount of work, but the browsers are really good at that — that’s basically what browsers are optimized to do, is parse HTML and turn it into trees. And it only touches the DOM once, from the JavaScript perspective, so even though it appears to be pretty inefficient, it’s actually quite efficient, comparatively. I recommend you make good use of Ajax libraries, particularly YUI — I’m a big fan of that. Effective coding reuse will make the widgets more effective.
So, this is how IE8 spends its time [diagram is displayed]. This was reported by the Microsoft team at the Velocity conference this year. So, this is the average time allocation of pages of the top 100 allexalwebpages. So they’re spending about 43% of their time doing layout, 27% of their time doing rendering, less than 3% of their time parsing HTML — again, that’s something browsers are really good at. Spending 7% of their time marshalling — that’s a cost peculiar to IE because it uses ActiveX to implement its components, and so there’s a heavy cost just for communicating between the DOM and JavaScript. 5% overhead, just messing with the DOM. CSS, formatting, a little over 8%. Jscript, about 3%. OK, so if you were really heroic, and could get your Jscript down to be really, really fast, most users are not even going to notice. It’s just a waste of time to be trying to optimize a piece of code that has that small an impact on the whole. What you need to think about is not how fast the individual JavaScript instructions are doing, but what the impact of those instructions have on the layout and rendering. So, this is the case for most pages on average — let’s look at a page which does appear to be compute bound.
This is the time spent for opening a thread on GMail, which is something that can take a noticeable amount of time. But if we look at the Jscript component, it’s still under 15%. So if we could get that to go infinitely fast, it still wouldn’t make that much of a difference. In this case, it turns out CSS formatting is chewing up most of the time. So if I were in the GMail team, running up this, I could be beating up my programmers saying ‘why is your code going so slow?’ or I could say ‘let’s schedule a meeting with Microsoft, and find out what we can do to reduce the impact of CSS expenditures in doing hovers, and other sorts of transitory effects,’ because that’s where all the time is going. So, that’s not a big deal. So you need to be aware of that when you start thinking about: ‘how am I going to make my application go faster?’
Now, there are some things which most language processors will do for you. Most compilers will remove common sub expressions, will remove loop invariants. But JavaScript doesn’t do that. The reason is that JavaScript was intended to be a very light, little, fast thing, and the time to do those optimizations could take significantly more time than the program itself was actually going to take. So it was considered not to be a good investment. But now we’re sending megabytes of JavaScript, and it’s a different model, but the compilers still don’t optimize — it’s not clear that they ever will. So there’s some optimizations it may make sense to make by hand. They’re not really justified in terms of performances, we’ve seen, but I think in some cases they actually make the code read a little better. So let me show you an example.
Here I’ve got a four loop, which I’m going to go through, a set of divs, and for each of the divs I’m going to change their styling — I’m going to change the color, and the border, and the background color. Not an uncommon thing to do in an Ajax application, but I can see some inefficiencies in this. One is, I have to compute the length of the array of divs on every iteration, because of the silly way that the fore statement works. I could factor that out — it’s probably not going to be a significant savings, but I could do that a bigger cost is, I’m computing divs by style on every itiration period. So I’m doing that three times per iteration — when I only have to do it once. And probably the biggest, depending on how big the length turns out to be, is that I’m computing the thickness parameter value on every iteration, and it’s constant, in the loop. So every time I compute that, except the first time, that’s a waste. I compute this loop this way. I create a border, which’ll precreate the thickness. Also, capture the number of divs. Then in the loop, I will also capture divs by style, so we’ll only have to get it once, and now I can change these things through that. To my eye, this actually read a little bit better — I can see border, yeah, this makes sense. I can see what I’m doing here. Do any of these changes affect the actual performance of the program? Probably not measurably, unless ‘n’ is really, really big. But I think it did make the code a little bit better and so I think this is a reasonable thing to do.
I’ve seen people do experiments where there are two ways you could say: a cat can eat a string. You need to use a plus operator, or you could do a ‘join’ on an array. And someone heard that ‘join’ is always faster, and so you see them doing cases where you concatenate two things together, they’ll make an array of two things and call ‘join’. This is strictly slower, this case, than that one. ‘Join’ is a big win if you’re concatenating a lot of stuff together. For example, if you’re doing an innerHTML build in which you’re going to build up, basically, a subdocument, and you’ve got a hundred strings that are going to get put together in order to construct that — in that case, ‘join’ is a big win. Because every time you call ‘+’, it’s going to have to compute the intermediate result of that concatenation, so it consumes more and more memory, and copies more and more memory as it’s approaching the solution. ‘Join’ avoids that. So in that case, ‘join’ is a lot faster. But if you’re just talking about two or three pieces being put together, ‘join’ is not good. So generally, the thing that reads the best will probably work, but there are some special cases where something like ‘join’ will be more effective. But again, it’s generally effective when ‘n’ is large — for small ‘n’, it doesn’t matter.
I recommend that you don’t tune for quirks. There are some operations which, in some browsers, are surprisingly slow. But I recommend that you try to avoid that as much as possible. There might be a trick that you can do which is faster on Browser A, but it might actually be slower on Browser B, and we really want to run everywhere. And the performance characteristics of the next generation of browsers may be significantly different than this one — if we prematurely optimize, we’ll be making things worse for us further on. So I recommend avoiding short term optimizations.
I also recommend that you not optimize without measuring. Our intuitions as to where our programs are spending time are usually wrong. One way you can get some data is to use dates to create timestamps between pieces of code — but even this is pretty unreliable. A single trial can be off by as much as 15ms, which is huge compared to the time most JavaScript statements are going to be running, so that’s a lot of noise. And even with accurate measurement, that can still lead to wrong conclusions. So measurement is something that has to be done with a lot of care. And evaluating the results also requires a lot of care.
[Audience member raises hand]
Douglas: Yeah? Oh, am I aware of any tools or instruments the JavaScript engine in the browsers so that you can get better statistics on this stuff? I’m not yet, but I’m aware of some stuff which is coming — new firebug plug—ins and things like that, which will give us a better indication as to where the time’s going. But currently, the state of tools is shockingly awful.
So, what do I mean when I talk about ‘n’? ‘N’ is the number of times that we do something. It’s often related to the number of data items that are being operated on. If an operation is performed only once, it’s not worth optimizing — but it turns out, if you look inside of it you may find that there’s something that’s happening more often. So the analysis of applications is strongly related to the analysis algorithms, and some of the tools and models that we can look at there can help us here.
So suppose we were working on an array of things. The amount of time that we spend doing that can be mapped according to the length of the array. So, there’s some amount of start up time, which is the time to set up the loop and perhaps to turn down the loop, on the fixed overhead of that operation. And then we have a line which descends as the number of pieces of data increases. And the slope of that line is determined by the efficiency of the code, or the amount of work that that code has to do. So a really slow loop will have a line like that [gestures vertically] and a really fast loop will have a line that’s almost horizontal.
So you can think of optimization as trying to change the slope of the line. Now, the reason you want to control the slope of the line is because of the axis of error. If we cross the inefficiency line, then a lot of the interactive benefits that we were hoping to get by making the user more productive, will be lost. They’ll be knocked out of flow, and they’ll actually start getting irritated — they might not even know why, but they’ll be irritated at these periods of waiting that are being imposed on them. They might not even notice, they’ll just get cranky using your application, which sets you up for some support phone calls and other problems — so you don’t want to be doing that. But even worse is, if you cross the frustration line. At this point, they become… they know that they’re being kept waiting, and it’s irritating, so satisfaction goes way down. But even worse than that is the failure line. This is the line where the browser puts up an alert, saying ‘do you want to kill the script?’ or maybe the browser locks up, or maybe they just get tired of waiting and they close the thing. This is a disaster, this is total failure. So you don’t want to do that either, so you want to not cross any of those lines, if you can avoid it — and you certainly never want to cross that one [gestures to failure line].
So to do that, that’s when you start thinking about optimizing: we’re crossing the line, we need to get down. One way we can think about it is changing the shape of the line. Sometimes if you change the algorithm, you might increase the overhead time of the loop — but in exchange for that, you can change the slope. And so, in many cases, getting a different algorithm can have a very good effect. Now, if the kind of data you’re dealing with has interactions in it, then you may be looking at an ‘n log n’ curve. In this case, changing the shape of the line won’t have much of a help. Or if it’s an n squared line, which is even worse — doubling the efficiency of this [gestures to point on line] only moves it slightly. So the number of cases that you can handle before you fail is only marginally increased by an heroic attempt to optimize — so that’s not a good use of your time.
So the most effective way to make programs faster is to make ‘n’ smaller. And Ajax is really good for that, Ajax allows for just—in—time data delivery — so we don’t need to show the user everything they’re ever going to want to see, we just need to have on hand what they need to see right now. And when they need to get more, we can get more in there really fast, by having lots of short little packets in this dialog.
One final warning is: The Wall. The Wall is the thing in the browser that when you hit it, it hurts really bad. We saw a problem in [Yahoo!] Photos, back when there was [Yahoo!] Photos [which was replaced by Flickr], where they were trying to do some…they had a light table, on which you could have a hundred pictures on screen. And then you could go to the next view, which would be another hundred pictures, and so on. And thinking they wanted to make it faster to go back and forth, they would cache all the structures from the previous view. But what they found was the next view — or, the first view, came up really fast, but the second view took a half second more, the next view took a second more, and then the next view a second and a half more, and so on. And pretty soon you reached the failure line. And it turned out that what they had done — intending to be optimizing, was actually slowing everything down. That the working set the browser was using, the memory it was using in order to keep all those previous views, which were being saved as full HTML fragments, was huge. And so the system was spending all of its time doing memory management, and there was very little time left for actually running the application. So the solution was to stop trying to optimize prematurely, and just try to make the basic process of loading one of these views as fast as possible. So the only thing that cached was the JSON data, which was pretty small, and they would rebuild everything every time — which didn’t take all that much time, because browsers are really good at that. And in doing that, they managed to get the performance down to a linear place again, where every view took the same amount of time.
These problems will always exist in browsers, probably. So the thing we need to be prepared to do is to back off, to rethink our applications, to rethink our approach. Because while the limits are not well understood, and not well advertised, they are definitely out there. And when you hit them, your application will fail, and you don’t want to do that. So you need to be prepared to rethink not only how you build the application, but even what the application needs to do — can it even work in browsers. For the most part, it appears to be ‘yes’, but you need to think responsively, think conversationally. The gaps don’t work very well in this device… So, that’s all I have to say about performance. Thank you.
The question was, did they have a way of flushing what they were keeping for each view? And it turned out they did. What they did was, they built a subtree in the DOM for each view of a hundred images, a hundred tiles, and they would disconnect it from the DOM and then build another one, and keep a pointer to it, so they could reclaim it. And then they’d put that one in there. And so they had this huge set of DOM fragments. And that was the thing that was slowing them down. Just having to manage that much stuff was a huge inefficiency for the browser. And they did that thinking they were optimizing — so that when you hit the back button, boom — everything’s there, and they can go back really fast. And then if you want to go forward again, you can go really fast. So they imagined they wanted to do that, and do that really effectively, but it turned out trying to enable that prevented that from working. So a lot of the things that happen in the browser are counterintuitive. So generally, the simplest approach is probably going to be the most effective.
That’s right, you don’t know what’s going to take the time — and so it becomes a difficult problem. You shouldn’t optimize until you know you need to. You need to optimize early, but you won’t be able to know until the application is substantially done. So, it’s hard.
Audience member: So it’ a matter of stay open to…
Douglas: That, and trying to stay in [...]. If you can keep testing constantly throughout the process, not wait until the end for everything to come together, that’s probably going to give you the best hope of having a chance to correct and identify performance problems.
Right, so the question is where to do paginations, essentially. Or caching. So, once approach is to have the server do the paginations, so it sends out one chunk at a time — and most websites work that way, because that’s the most responsive way to deliver the data. I can deliver 100 lines faster than I can deliver 1,000 lines, and so users like that — even though it means that they’re going to have to click some buttons to see the other 90% of it, people have learned to do that. The other approach is, take the entire data set and send that to the browser, and let the browser partition it out. And that has pretty much the same performance problems as the other approach, where we send all 1,000 in one page. What I recommend is doing it in chunks, and each chunk can be a pair of JSON messages, and request the chunks as you need them. That appears to be the fastest way the present the stuff to the user. Now, it’s harder to program that way — it’s easier for us if it’s one complete data set, and then we go ‘oh, we’ll just take what we need from that’. So that’s easy for us, but it does not give us the best performance. And as the data set gets bigger, it’s certain to fail.
Right. So, can we use canvass and CVS tricks to do well, is that a more effective way to accomplish that? Probably, at least in the few browsers that implement them currently. Over time, the browsers are promising to take better advantage of the graphics hardware, which standard equipment now on virtually all PCs — so it’s unlikely that we’ll be able to get that performance boost directly from JavaScript. So it’s likely that it’s going to be on the browser side, and those sorts of components. So eventually, that’s probably going to be a good approach — although it’s not clear how well that stuff’s going to play out in the mobile devices, and that’s becoming important too, so everything’s probably going to get harder and more complicated. That’s the forecast for 2009.




 xml.js
xml.js invalid-file
invalid-file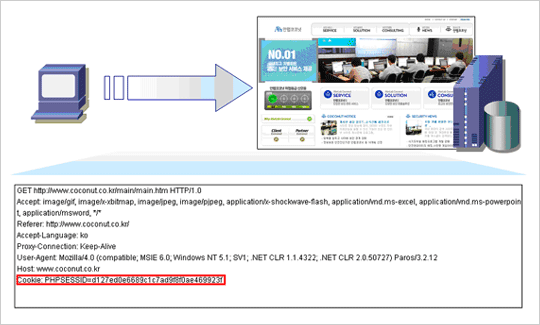



 invalid-file
invalid-file